前情提要
这篇主要介绍 SSD 的读写单位如 page、 block,以及写入放大 (write amplification) 、 wear leveling 等 SSD 问题及设计。除此之外, Flash Translation Layer (FTL) 及其两个主要功能 logical block mapping, garbage collection (gc)。也以 hybrid log-block mapping 设计当例子介绍 FTL 如何实际进行一个 flash 的写入操作。
如果是我的笔记会像这样加注在 info 栏位。
3. SSD 的基本操作
3.1 读、写、抹
因为 nand flash 的物理特性, flash memory 存取时必须要遵循特定规则,如果我们了解这些特性对我们在最佳化资料结构设计时会有帮助。
- SSD 读取以分页 (page) 为基本单位,即便你只是要读一个 byte,还是会回传一个 page。
- 写入也以 page 为单位,即便你只有写入小量资料,实际进行物理写入时 SSD 还是要写一个 page,此类现象也称为写入放大。 write, program 在 SSD 期刊上指的是同一件事。
- copy-modify-write: 已有资料的 page 不能被直接复写,当需要更改 page 资料时,要不是写在该 blcok 空白/free 的 page 里,然后把该 page 标示为 stale,或是将整个 block 复制到 mem 修改,再写到其他空的 block 去。 stale 的 block 必须在其他时机点清空。
- 资料抹除必须以 block 为单位。一般使用者在读写资料时 SSD 不会实际把 stale 资料物理上抹除,SSD也只有进行 read/write 操作。SSD 只在 GC 判断需要清出空间时对 nand flash 执行抹除/erase 指令。
3.2 写入范例
图中得 2 看到我们在写入 x’ 的时候不是复写 x,而是 free 的 page 1000-3。
3 则是 GC 的操作,把 1000 清为 free,原有资料放到另一个 block,并清除 stale page。

这里可以猜测 SSD controller 需要很多储存 lba -> pba 的资料结构.
3.3 写入放大
写入小于 page size 的资料会造成 write amplification 的空间浪费([13])[#ref], 写入 1 B 变成 16 KB。此类写入放大也会在后续 GC, wear leveling 中持续传递。我们也可能写入一个 page 的资料量但是 address mapping 结果没有对在 page 开始处,最后要用到两个 page,并可能触发 read-modify-write,让效能变差[2, 5]。
作者给了几个建议:永远不要写入小于一个 page size 的资料,写入的资料两大小与 page size 成倍数为原则、小的大量写入先做缓存再批次写入。
3.4 wear leveling
因为 SSD cell 有 P/E life cycle 限制,如果我们一直都读写同个 block, cell 挂了,SSD 容量会随着使用一直变少。 wear leveling 就是要让使用次数平均分配到各个 block 去[12, 14]。 为了做到 wear leveling, controller 在写入时需要依 page 写入次数来选择,必要时也有可能将各个 block 的资料做调动,也是一种 write amplification。 block 管理就是在 wear leveling 跟 write amplification 之间做取舍。 SSD 制造商想出了各种方法来解决这类问题,让我们继续看下去。
有点像在整理房间一样,各个原则都有好有坏 XD。
4 Flash Translation Layer (FTL)
4.1 FTL 的必要性
SSD 可以很快导入是因为他走 HDD 的 Logical Block Addresses (LBA) ,上层软件/档案系统不用因为 SSD 做调整。 上面提到SSD 不如 HDD 各个 sector/page 可以直接被复写,所以 FTL 横空出世来解决这个问题,把 SSD 操作细节藏起来,让 host interface 依然只需要对不同的 LBA 做存取,不用管 copy-modify-write, level wearing 等事。
amd64 与 x86 的演进感觉也是类似的关系,向后相容非常重要。谁跟你换个硬件/架构就软件全部重写啊 XD。
4.2 LBA to PBA
controller 工作其一就是把 host interface 的 logical block address 转physical address。这类资料结构通常是存成一个 table ,为了存取效率,这类资料会缓存在 controller 的 memory 里,并提供断电保护。[1,5]
实作方法有
page level mapping,最有弹性。每个 page 都对应到各自的 physical page,缺点是需要更大的 ram 来存 mapping table,太贵。
为解决上述问题,block level mapping 节省 mapping table 的 ram。整个做法大幅降低了 mapping table ram 用量,但是每次写入都需要写入一个 block,面对大量小资写入放大岂不崩溃[1,2]。
上面的 page vs black 的战争就是空间换取时间之间的取舍。有些人开始说这样不行,我全都要:有了混合的 log-block mapping ,面对小资写入会先写到 log 缓存区,log存到一定量再合并成 block 写下去[9, 10]。
下图是一个简化版本的 hybrid log-glock FTL 实作。写了四个 full page 大小的资料,Logical page # 5, 9 都对应到 logicl block number(LBN) 1,此时关联到一个空的 physical block #1000。 一开始 log-block page mapping table 1、 block #1000 是空的,随着写入资料到 block 1000 的过程 physical page offset 会新增/更新其对应位置。 #1000 也称为 log block。
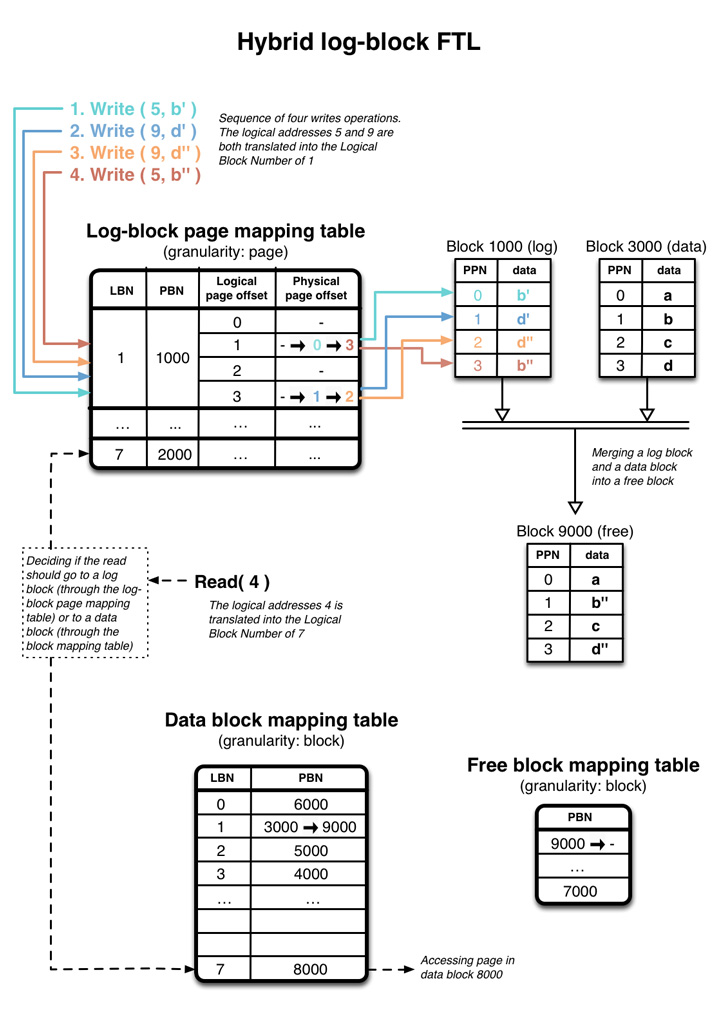
当 log block #1000 写满了之后, controller 会将原有的 data block #3000 与 log block #1000 合并,写到空的 data block #9000,此时 #9000 成了 data block。
值得注意的是这个方法消除了四个写入 b’, d’, b’’, d’’ 可能带来的写入放大,而且合并 block 的时候,新的 block #9000 拿到的是新的资料 b’’, d’’.
最后读取指令会看现在资料是在 log block 来回传资料,若否则去查 data-block mapping table(图左下方)
log-block 在我们刚好写入完整的 block 的时候也可以直接省去跟 data block 合并的功夫,直接更改 data-block mapping table 的 metadata,并把原有的 data block 清空,更新为 log block。这类最佳化手段也称为 switch-merge, swap-merge。
目前对 log-block 的研究很多:FAST (Fully Associative Sector Translation), superblock mapping, flexible group mapping [10]。其他的 mapping 手法也有如 Mitsubishi algorithm, SSR [9]。
这类 hybrid log-block 的作法,作者说很像 log-sructured 档案系统,一个例子是 zfs。 自从 proxmox ve 开始接触 zfs ,觉得他真的很好用… 从 ubuntu 19.10 开始可以直接把 rootfs 用 zfs 装喔。
4.3 2014 业界状况
当时 wikipedia 有 70 间 SSD 厂商, 11 间有能力做 controller, 其中4 间有自有品牌(Intel, Samsung, …),另外 7 间专做 controller 的公司占了 90% 的市场销量[64, 65]。
wiki 上 2019 年变成 12 家,而自有品牌的有 5 间 WD、Toshiba、Samsung、Intel、威盛电子。 台湾的 controller 厂商有 phison, slicon motion, VIA tech, realtek, jmicron
作者不确定是哪几间公司吃下这个市场,但他以 Pareto(80/20) 法则猜应该是其中的两三家,所以从除了自有品牌的 SSD,用同一个 controller 大概行为都会差不多。FTL 的实作对效能影响甚钜,但是各家厂商也不会公开自己用了哪些方法实作。
作者对于了解或是逆向工程[3] mapping schema 的实作对提升应用层程式的效能保持保留态度。毕竟市面上的 controller 厂商大多没有开放实作细节,就算针对某个 policy 去调整程式设定更甚至你拿到原始码,这套系统在其他 schema 或是其他厂牌下也不一定有更好的结果。唯一的例外可能是你在开发嵌入式系统,已经确定会用某厂商的晶片。
作者建议大抵上知道许多的 controller FTL 是实作 hybrid log block policy 就好了。然后尽量一次写入至少一个 block size 的资料,通常会得到较好的结果。
4.4 Garbage Collection
因为将 page 清为 free 的抹除(erase)指令 latency 较高(1500-3500 μs, 写入 250-1500 μs),大部分的 controller 会在闲暇时做 housekeeping,让之后写入作业变快[1],也有一些实作是在写入时平行进行[13]。
时常会遇到 foregound 频繁小档写入影响 background,导致找不到时间做 GC 的情况。这时候TRIM command, over-provisioning 可以帮得上忙(下一篇会介绍)。
flash 还有一个特性是 read disturb,常读一个 block 的资料会造成 flash 状态改变,所以读了一定次数以后也需要搬动 block [14]
另外当一个 page 里面有不常改的 cold/static data 及 hot/dynamic data,hot data 的更动会让他们一起被搬动,分开冷热资料可以改善这类情况。(不过冷的资料放久了还是会因 wear leveling 被动)。 另外也因为资料冷热是应用层的事,SSD 不会知道,改善 SSD 效能的一个方法便是冷热分开在不同的 page里,让 GC 好做事。
作者也建议 “非常热” 的资料可以先 cache 起来再写到硬盘。以及当有资料不再被需要、或是需要删除的时候可以批次进行,这让 GC 可以一次得到比较多的空间操作,降低空间碎片化。
所以很多人提倡电脑换了要把硬盘丢到调理机里面,这点在 SSD 也不例外 XD
ref
其他有编号参考资料请至原文观赏:link