原文链接:顶会FAST’26解读|ZUFS:旗舰手机的下一代存储革命 来源:存储随笔
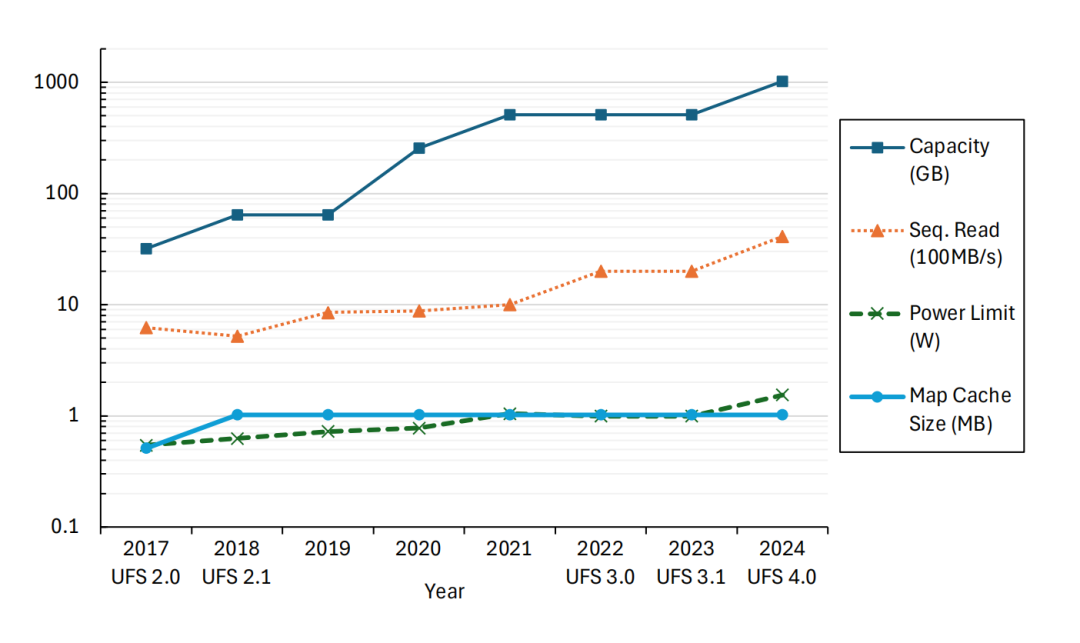
当我们讨论旗舰手机的性能时,目光往往聚焦于SoC、内存、屏幕,却常常忽略了一个决定整机体验下限的核心组件——存储。从2017年UFS 2.0到2024年UFS 4.0,手机连续读取带宽从几百MB/s飙升到4.2GB/s,容量从32GB跃升至1TB甚至2TB,但一个致命的底层瓶颈,始终没有被真正解决:传统UFS(CUFS)的逻辑-物理(L2P)映射开销,正在让越来越强的硬件性能,在日常使用中被严重损耗。
2026年USENIX FAST顶会上,来自SK海力士、谷歌、首尔国立大学的联合团队,发布了《Unleashing Zoned UFS: Cross-Layer Optimizations for Next-Generation Mobile Storage》这篇重磅论文。 它不仅完整拆解了Zoned UFS(ZUFS)这一下一代移动存储技术的核心原理,更首次公开了其从实验室到谷歌Pixel 10 Pro系列量产落地的全栈优化方案,用实测数据证明:ZUFS能在碎片化场景下实现2倍以上的写入吞吐量,让《原神》加载速度提升14%,相册滑动卡顿率降低57%。 这篇文章,带你从底层原理到量产落地,深度拆解ZUFS这项技术,搞懂它到底解决了什么问题,用了哪些核心创新,又会给未来的旗舰手机带来怎样的行业变革。

扩展阅读:
- ZNS SSD垃圾回收优化方案解读
- ZNS SSD+F2FS文件系统|如何降低GC开销?
- ZNS SSD是不是持久缓存的理想选择?
- 为什么QLC NAND才是ZNS SSD最大的赢家?
- NVMe SSD:ZNS与FDP对决,你选谁?
一、传统UFS的”生死劫”:性能越强,短板越明显
在拆解ZUFS之前,我们必须先搞懂:已经迭代到4.0的UFS,到底遇到了什么无法突破的底层瓶颈?
UFS早已成为安卓旗舰的标配,它凭借全双工串行接口、命令队列机制,彻底取代了老旧的eMMC,实现了带宽的指数级增长。但从2017年到2024年,UFS设备的容量从32GB涨到1TB,顺序读取带宽从几百MB/s冲到4.1GB/s,用于存放L2P映射表的on-die-SRAM,却始终停留在1MB左右,这就是所有问题的根源。
1. 映射表开销:1TB存储需要1GB映射表,SRAM根本装不下
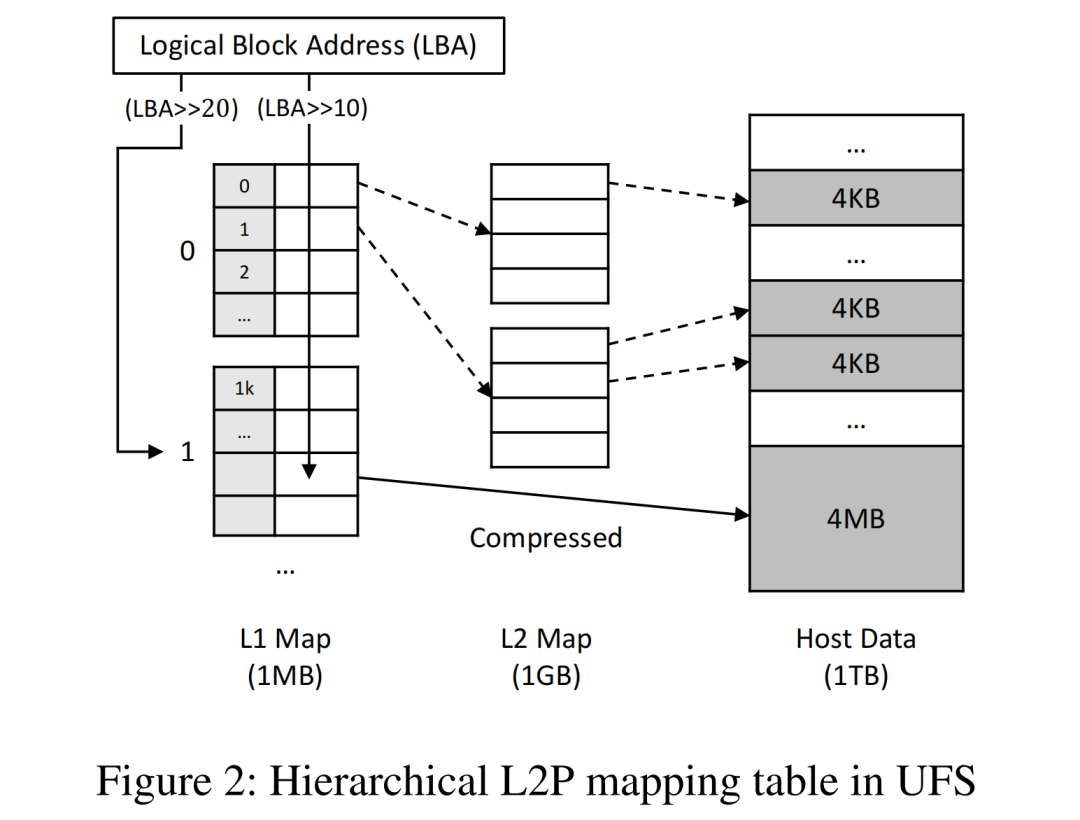
NAND闪存的”先擦后写”特性,决定了闪存设备必须通过闪存转换层(FTL)维护L2P映射表,实现逻辑块地址(LBA)到物理页地址(PPA)的转换。传统UFS采用页级映射,每个4KB逻辑页对应一条映射条目,这带来了极致的灵活性,但也产生了惊人的开销:
1TB容量的UFS,完整的页级映射表需要约1GB的存储空间;但手机UFS控制器的片上SRAM仅1MB左右,根本无法存放完整映射表,只能通过”映射缓存”机制,把常用的映射条目放进SRAM,不常用的放在NAND闪存里。这就导致了一个致命问题:当手机进行大范围随机读写(比如游戏资源加载、相册大图浏览)时,映射缓存频繁失效,必须从NAND闪存里读取映射条目,直接造成读写延迟暴涨、性能暴跌。哪怕你的UFS 4.0标称带宽再高,日常使用中也根本跑不满。

2. 碎片化:30%的旗舰机,都在承受严重的性能损耗
很多人有一个误区:”闪存不存在碎片化问题”。但事实恰恰相反,手机存储的碎片化,是日常使用卡顿的核心元凶之一。
论文团队调研了1万台上市1年的旗舰手机,得出了一个颠覆认知的结论:
- 约30%的设备,碎片化水平超过0.7(数值越接近1,碎片化越严重)
- 哪怕存储利用率低于30%,依然有大量设备存在严重碎片化,碎片化和利用率的相关系数仅0.74,说明它不是”存储满了才会出现的问题”
- 碎片化水平超过0.4后,读取延迟的方差显著增大;超过0.8后,写入性能断崖式下跌,写入延迟99分位达到678ms/MB,最坏情况甚至接近2s/MB
碎片化不仅会让FTL的映射缓存效率进一步下降,还会触发频繁的垃圾回收(GC),而前台GC会直接阻塞用户I/O,造成肉眼可见的卡顿、掉帧。

3. 写放大与功耗:设备级GC吃掉了闪存寿命和续航
传统UFS的FTL必须在设备端执行GC,来回收无效数据块。这不仅会带来严重的写放大(WAF),缩短闪存寿命,还会在GC过程中消耗额外的功耗,对于电池容量受限的手机来说,这是无法忽视的短板。
更关键的是,随着端侧AI的兴起,手机需要频繁加载大模型权重、处理实时AI任务,对存储的随机读稳定性、低延迟、低功耗提出了前所未有的要求。传统UFS的架构,已经走到了性能和能效的天花板。
二、ZUFS到底是什么?给移动存储做一次”底层重构”
为了解决传统UFS的核心痛点,JEDEC在2023年11月正式批准了ZUFS规范,将分区存储模型引入UFS标准,给移动存储做了一次彻底的底层重构。
1. ZUFS的核心原理:用分区顺序写,干掉页级映射开销
ZUFS的核心逻辑非常简洁:把UFS的地址空间划分为多个固定大小的分区(Zone),每个分区内的写入必须严格遵循顺序写入规则,每个分区都有一个写指针,记录下一个可写入的位置。
这个看似简单的规则,带来了颠覆性的改变:
- 映射表粒度从”4KB页级”变成”1GB分区级”,1TB容量的ZUFS,完整的分区映射表(ZMT)仅需要8KB,完全可以放进1MB的片上SRAM里,彻底消除了映射缓存失效的问题
- 分区大小和NAND擦除块对齐,设备端的GC被完全消除,GC的职责上移到主机端的文件系统,大幅降低了写放大,提升了闪存寿命和能效
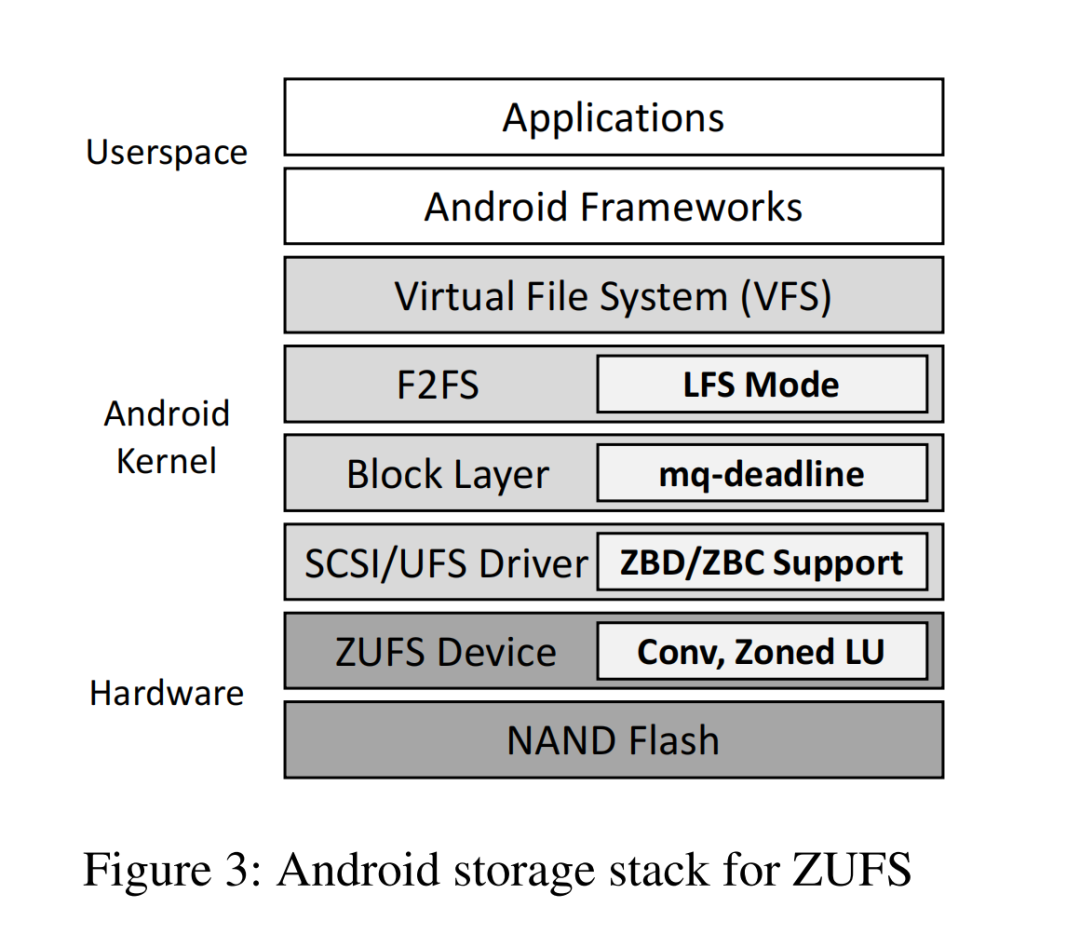
- 安卓默认使用的F2FS文件系统,本身就是日志结构设计,天生和ZUFS的顺序写入规则契合,无需大规模修改软件栈,就能实现无缝适配

2. ZUFS≠服务器ZNS SSD,手机场景的挑战要大得多
很多人会问:分区存储不是早就用在数据中心的ZNS SSD上了吗?ZUFS只是把它搬到手机上而已?
事实绝非如此。数据中心的ZNS SSD,往往配备了GB级的DRAM来存放元数据,还能给每个打开的分区分配独立的写入缓冲区;但手机UFS控制器的SRAM极其稀缺,功耗、面积预算都被严格限制,这就导致ZUFS的落地,面临着ZNS SSD从未遇到过的专属挑战。
论文团队也明确指出:ZUFS的全部潜力,只有通过整个移动存储栈的协同重构,才能真正实现。
三、理想很骨感:ZUFS量产落地的三大致命挑战
看似完美的ZUFS,在商用旗舰手机的落地过程中,遇到了三个横跨设备固件、驱动、文件系统、安卓框架的核心障碍,这也是此前ZUFS无法量产的核心原因。
挑战一:多分区并发的SRAM缓冲区颠簸
JEDEC规范要求ZUFS至少支持6个并发打开的分区,这刚好匹配F2FS的默认设计——通过6个分区,按冷热程度分离数据和元数据。
但问题来了:论文中测试的ZUFS设备,一个完整的跨所有Die和Plane的SuperPage超大页,需要768KB的写入缓冲区。6个并发分区就需要4.6MB缓冲区,再加上常规逻辑单元的缓冲区,总需求超过5MB,这对于仅有几MB SRAM的UFS控制器来说,完全是不可能完成的任务。
如果采用静态分配,给每个分区分配固定的小缓冲区,就会导致频繁的非对齐刷写,造成缓冲区颠簸、性能暴跌、写放大飙升;而此前业界提出的ZMS方案,需要在主机端增加IOTailor内核模块,聚合写入请求后再下发,不仅增加了主机CPU和DRAM开销,还和安卓的文件级加密机制冲突,无法上游到开源社区,根本不具备量产可行性。
挑战二:端到端写入顺序被频繁打破
ZUFS的正常运行,高度依赖”分区内严格顺序写入”的规则,一旦写入顺序被打乱,就会直接触发非对齐写入错误,导致数据写入失败。
但安卓的存储栈里,到处都是打破写入顺序的”坑”,其中最致命的,就是手机的激进电源管理机制。UFS控制器为了省电,会在空闲时启用时钟门控(Clock Gating),关闭设备时钟;当新的写入请求到来时,请求会被暂时驳回,重新排队等待时钟恢复,这个过程会直接打乱原本的写入顺序。
除此之外,Linux块层的mq-deadline调度器,在请求重排队、FUA强制写入标志、IO优先级调度等多个边角场景中,都可能打破写入顺序,给ZUFS带来致命的正确性风险。

挑战三:大分区带来的灾难性GC开销
大分区是ZUFS的核心优势之一:分区越大,越能充分利用UFS的多Die并行性,对齐NAND擦除块后,还能彻底消除设备级GC。
但大分区也给主机端的F2FS带来了灾难性的GC开销:
- 分区越大,单次GC需要迁移的有效数据就越多,迁移成本和写放大大幅飙升
- 分区越大,可分配的分区数量就越少,空闲分区会更快耗尽,导致前台GC被频繁触发,直接阻塞用户I/O,造成严重卡顿
这三个挑战,就像三座大山,挡在了ZUFS的量产落地之路上。而论文团队的核心贡献,就是通过横跨设备固件、SCSI/UFS驱动、块层、F2FS文件系统、安卓框架的全栈跨层优化,彻底解决了这三个问题,让ZUFS真正实现了商用落地。
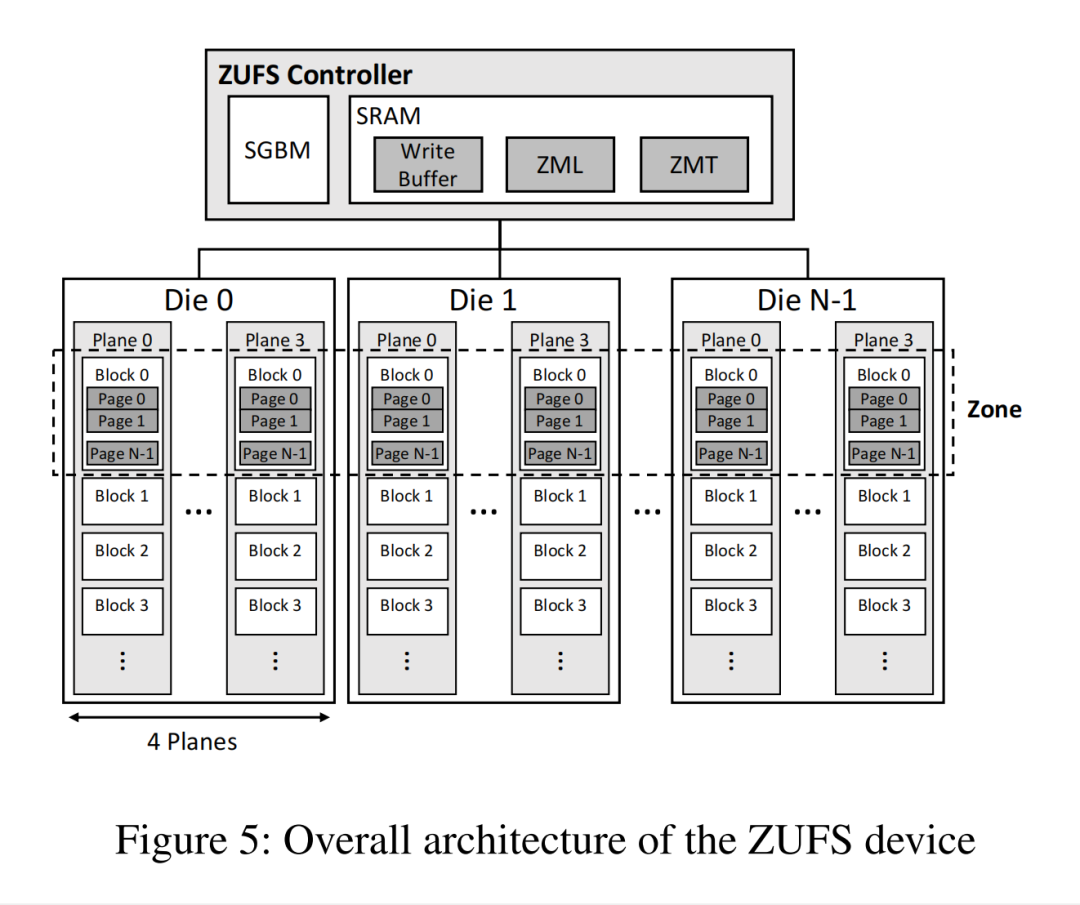
四、全栈破局:三大核心创新,解锁ZUFS的全部潜力
针对上述三大挑战,论文团队提出了三套针对性的解决方案,从硬件到软件,从设备端到主机端,完成了全链路的优化,并且所有代码都已经上游到Linux内核和安卓开源项目,为全行业的适配铺平了道路。
创新一:分区感知动态缓冲区管理(ZABM),零主机开销解决缓冲区颠簸
针对SRAM缓冲区不足的问题,团队没有走主机端聚合的老路,而是直接在UFS控制器里,设计了一套硬件级的散列-聚集缓冲区管理器(SGBM),实现了细粒度的动态缓冲区分配。
这套方案的核心逻辑非常巧妙:
- 把UFS控制器里预留的SRAM,切分成一个个4KB的最小槽位,SGBM硬件模块专门负责槽位的分配、追踪和释放
- 每个打开Open的分区,都会分配一个槽位表,记录分配给该分区的槽位索引,无需给每个分区预留完整的768KB SuperPage超大页缓冲区
- 当写入请求到来时,SGBM把数据写入空闲槽位,追加到对应分区的槽位表里
- 当单个Die的192KB数据写满时,立刻刷写到NAND闪存,无需等待768KB的完整SuperPage超大页写满
- 当SuperPage超大页数据全部写满时,SGBM会调度并行刷写,充分利用UFS的多Die并行性
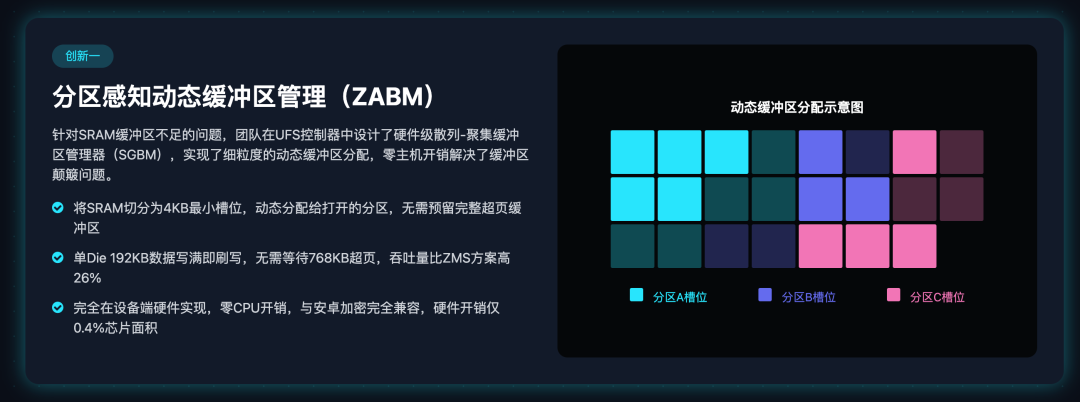
这个设计带来了颠覆性的优势:
- 彻底解决了缓冲区颠簸问题,每个分区只占用最小的SRAM footprint,高负载分区可以动态申请更多槽位,SRAM利用率达到极致
- 完全在设备端硬件实现,无需主机端做任何修改,零CPU/DRAM开销,和安卓加密机制完全兼容,具备完美的上游适配性
- 硬件开销极低,仅占用UFS控制器芯片0.4%的面积,几乎可以忽略不计
- 实测吞吐量比ZMS方案高出26%,哪怕限制768KB的刷写块大小,依然能全面领先ZMS

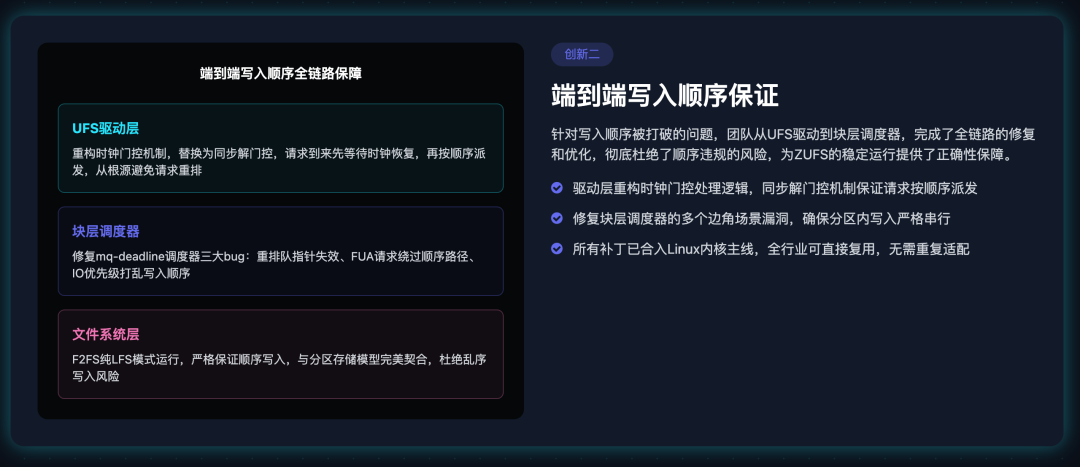
创新二:端到端写入顺序保证,从驱动到调度器全链路堵上漏洞
针对写入顺序被打破的问题,团队从UFS驱动到块层调度器,完成了全链路的修复和优化,彻底杜绝了顺序违规的风险。
核心优化分为两部分:
UFS驱动时钟门控机制重构: 把原本的请求重排队机制,替换成同步解门控机制。当新的I/O请求到来时,驱动会先等待设备时钟完全恢复,再按顺序派发请求,从根源上避免了时钟门控导致的请求重排。
mq-deadline调度器三大bug修复:
- 修复了请求重排队后,next_rq指针失效导致的调度顺序错乱
- 修复了带FUA标志的请求绕过顺序路径,导致的写入重排
- 修复了IO优先级调度打乱分区写入顺序的问题,确保分区内的写入严格串行
这些修改,让安卓存储栈从文件系统下发请求,到UFS设备执行写入,全链路都能严格保证写入顺序,为ZUFS的稳定运行提供了正确性保障。目前这些补丁已经全部合入Linux内核主线。
创新三:主动式自适应GC框架,解决大分区的GC开销灾难
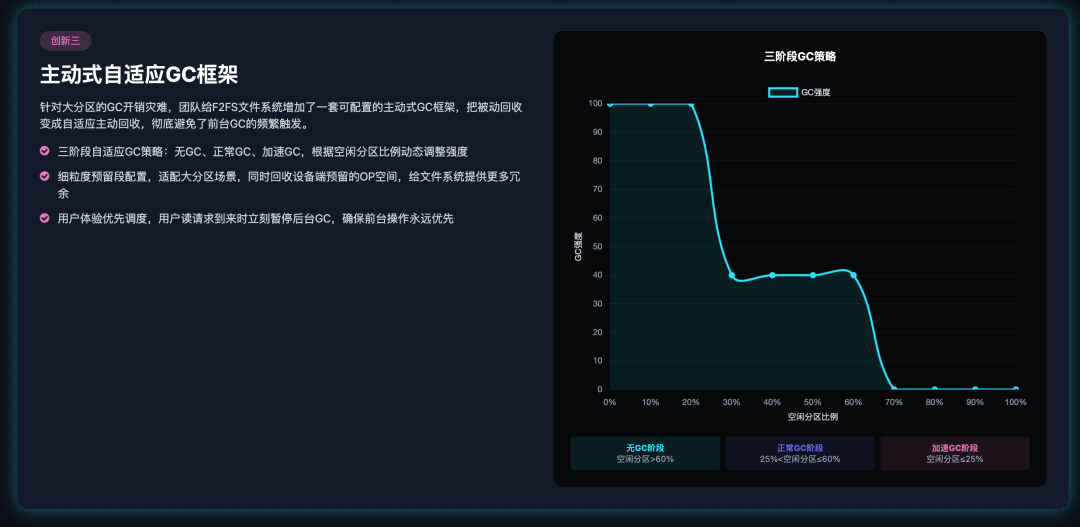
针对大分区带来的GC问题,团队给F2FS文件系统增加了一套可配置的主动式GC框架,把原本”被动回收”的GC,变成了”自适应主动回收”,彻底避免了前台GC的频繁触发。
这套框架的核心设计包括:
三阶段自适应GC策略: 通过可调参数,把后台GC分成三个阶段,根据空闲分区的比例动态调整GC强度:
- 无GC阶段:空闲分区比例超过60%时,关闭后台GC,最大化I/O响应速度
- 正常GC阶段:空闲分区比例低于60%时,启动后台GC,只回收有效块比例低于95%的分区,单次扫描3个段
- 加速GC阶段:空闲分区比例低于25%时,启动激进GC,扫描窗口扩大5倍,切换到贪心算法,快速回收空闲空间
细粒度预留空间配置: 把原本CUFS里粗粒度的”预留分区”配置,改成了段粒度的预留段配置,默认预留6336个段,刚好满足6个打开分区的两倍需求,适配大分区的场景。
用户体验优先的调度机制: 只要有用户读请求下发,后台GC立刻暂停,确保前台用户操作的响应速度永远优先于空间回收。
这套主动GC框架,让F2FS在ZUFS的大分区场景下,始终能维持足够的空闲分区,彻底避免了前台GC的触发,哪怕在高碎片化场景下,也能维持稳定的写入性能。
五、实测见真章:从基准测试到真实场景的性能飞跃
所有的优化,最终都要落到实际性能上。团队在谷歌Pixel 10 Pro商用手机上完成了全量测试,设备配备12GB LPDDR5X内存、512GB ZUFS,运行安卓16系统和6.6版本内核,对照组为相同硬件的传统UFS(CUFS)模式,确保测试的公平性。
1. 基础性能:干净设备下与CUFS持平,底子不弱
在全新无碎片化的设备上,ZUFS的顺序读写、随机读写吞吐量,和CUFS基本持平。这说明ZUFS的优化,没有牺牲基础峰值性能,在理想场景下能完全发挥NAND闪存的原生带宽。
2. 大范围随机读:彻底消除映射缓存失效,性能全程稳定
在4GB到256GB的大范围随机读测试中,ZUFS的优势彻底体现出来:
- 4GB小范围访问时,CUFS和ZUFS性能接近,因为此时映射缓存几乎不会失效
- 随着访问范围扩大,CUFS的吞吐量持续暴跌,因为大范围随机访问导致映射缓存频繁失效,必须反复从NAND读取映射表
- ZUFS的吞吐量全程保持稳定,因为8KB的分区映射表完全存放在SRAM里,不存在任何缓存失效的问题
在4KB-128KB的中小块随机读测试中,ZUFS全面领先CUFS,这正是日常使用中最常见的I/O场景,比如应用启动、游戏资源加载、相册浏览等。
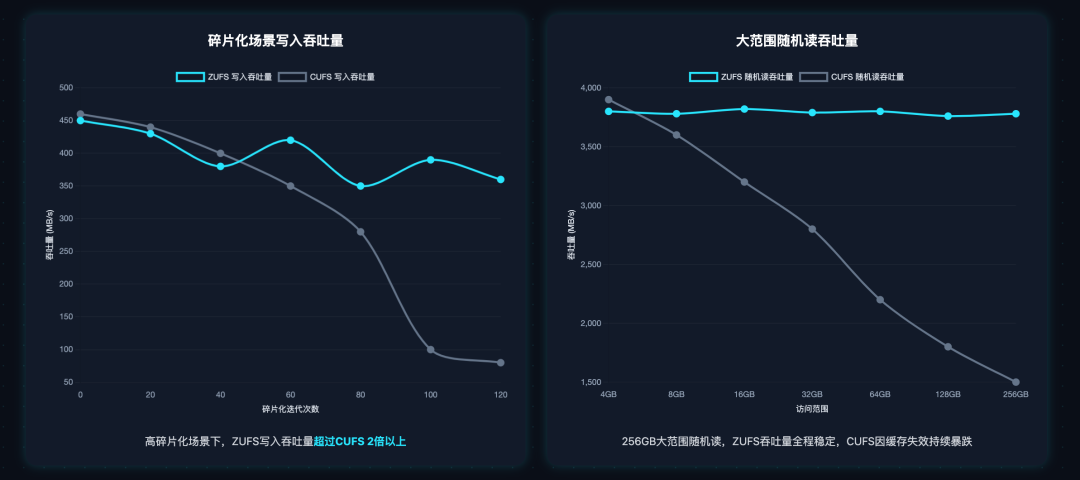
3. 高碎片化场景:写入吞吐量超CUFS 2倍,读取性能零衰减
团队通过迭代写入-删除操作,模拟了手机长期使用后的高碎片化环境,测试结果堪称碾压:
- CUFS在90次迭代后,写入吞吐量暴跌到接近100MB/s,读取吞吐量下降35%,因为空闲分区耗尽,前台GC频繁触发,严重阻塞I/O
- ZUFS的写入吞吐量,全程维持在200MB/s以上,最低值也超过CUFS的2倍
- 读取性能全程保持稳定,几乎没有任何衰减,因为主动GC在后台完成了空间回收,完全没有触发前台GC
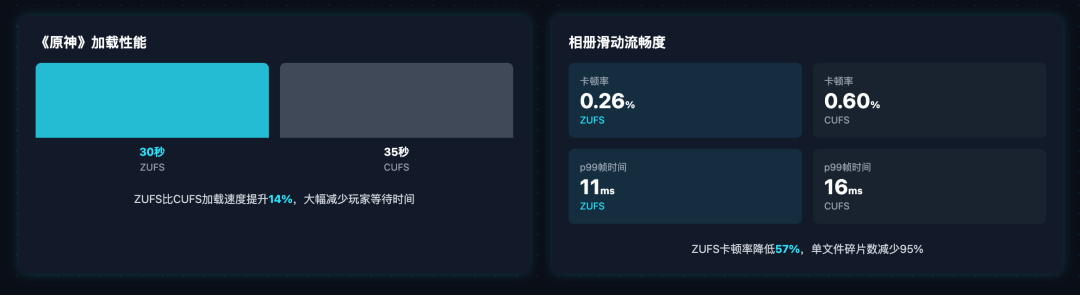
4. 真实应用场景:游戏加载更快,日常使用更流畅
在用户能直接感知的应用场景中,ZUFS的提升同样肉眼可见:
《原神》资源校验与加载: 在提前老化的碎片化设备上,ZUFS完成校验和加载仅需30秒,比CUFS的35秒快了14%。核心原因是CUFS的碎片化导致66.3%的读请求都是4-8KB的小块读取,而ZUFS的顺序写入特性,让绝大多数读请求都超过512KB,能充分发挥UFS的顺序读取带宽。
相册滑动流畅度: 在1300张照片的相册滑动测试中,ZUFS的卡顿率从CUFS的0.60%降到0.26%,降低了57%;单文件平均碎片数从46.29个降到2.31个,减少了95%;p99帧时间从16ms降到11ms,彻底告别了相册滑动的掉帧、卡顿。
六、不止于Pixel:ZUFS会成为移动存储的未来吗?
这篇论文的价值,绝不仅仅是实验室里的技术突破,更在于它已经完成了从技术到量产的落地——2025年发布的谷歌Pixel 10 Pro系列,已经全系搭载了这套ZUFS优化方案,成为全球首款商用ZUFS技术的高端旗舰手机。
而对于整个安卓行业来说,ZUFS的普及,只是时间问题,核心原因有三点:
开源生态已经铺平道路: 团队的所有修改,都已经上游到Linux内核和安卓开源项目,安卓16及通用内核6.6/6.12已经官方支持ZUFS,手机厂商无需从零开始适配,大幅降低了落地门槛。
大容量存储的刚需: 未来旗舰手机的存储容量会快速向2TB、4TB迈进,传统UFS的映射表开销会呈指数级增长,而ZUFS的映射表开销几乎不会随容量增长,天生适配大容量存储的趋势。
端侧AI的爆发式需求: 端侧大模型、AI生成式应用,对存储的随机读稳定性、低延迟、低功耗提出了极高的要求,而ZUFS彻底解决了映射缓存失效的问题,能为端侧AI提供稳定的存储性能支撑。
当然,ZUFS的普及,依然需要产业链的协同:从JEDEC标准的持续迭代,到SK海力士、三星等存储厂商的ZUFS设备量产,再到SoC厂商、手机厂商的全栈适配。但谷歌和SK海力士已经给行业打了样,证明了ZUFS的商用可行性和体验提升。
写在最后
从eMMC到UFS,移动存储用了十年时间,完成了带宽的数量级飞跃;而从CUFS到ZUFS,移动存储正在完成一次底层架构的彻底重构,解决了传统UFS十年都没能突破的核心瓶颈。
很多人说,现在的旗舰手机已经”性能过剩”,但事实上,我们的日常体验,依然被很多底层的技术短板所限制。ZUFS的出现,不是为了让跑分数字更高,而是为了让手机用了一年、两年之后,依然能保持刚开箱时的流畅,让游戏加载更快,让相册滑动不卡顿,让端侧AI的体验更丝滑。
这,才是技术创新真正的意义:不是为了参数的堆砌,而是为了用户体验的本质提升。而ZUFS,大概率会成为下一代安卓旗舰手机的标配,开启移动存储的全新十年。