从向量数据库到 ANN search
LLM的模型的爆火,意外带动了向量数据库的热度。之前名不见经传的一些初创公司也突然备受追捧。最近在分析端侧LLM场景的时候也分析了相关的一些向量数据库的相关知识。
GPT的缺陷
chatgpt在对话过程中表现出的能力包括了一定的上下文检索能力。但这个能力是基于LLM本身的上下文理解能力完成的,但受限于多数模型是基于kv cache结构的记忆历史对话信息的,kv cache size是有限的,在长程记忆上就天然存在一些缺陷。另一方面,在跨对话的场景下,这些上下文信息也不能使用。如果在端侧作为一个数字助理的场景来看,这显然是不合格的。
不同模型对于 token 的限制也不同,gpt-4 是 32K tokens 的限制,而目前最大的 token 限制是 Claude 模型的 100K,这意味可以输入大约 75000 字的上下文给 GPT,这也意味着 GPT 直接理解一部《哈利波特》的所有内容并回答相关问题。
这时候就可能觉得,那我把上下文信息一起发给LLM模型不就可以了。这就到了向量数据库的场景范畴了。在处理用户输入的时候,先去通过向量查找得到一些相关信息,一起输入给LLM模型,这样就可以正确回答相关信息了。
ANN Search
向量数据库说起来并不是一个新鲜的技术了,在统计机器学习时代,做KNN算法的时候就已经在研究相关的技术了。这里就简要的介绍一下原理和算法。
ANN搜索(Approximate nearest neighbor), 本质上是在很多稠密向量中,迅速找到目标点的临近点,并认为这认为是相似的节点,主要用于图像检索、高维检索。这里隐含了一个假设,映射在同一向量空间且距离相近的点,具有相似的语义特征,距离越近越相关,反之关系越远。
当前 ANN 搜索的方法大都是对空间进行切分,可以迅速找到子空间,并与子空间的数据进行计算。方法主要有基于树的方法、哈希方法、矢量量化、基于图的方法。
基于树的方法
基于树的方法最经典的就是KD树了。
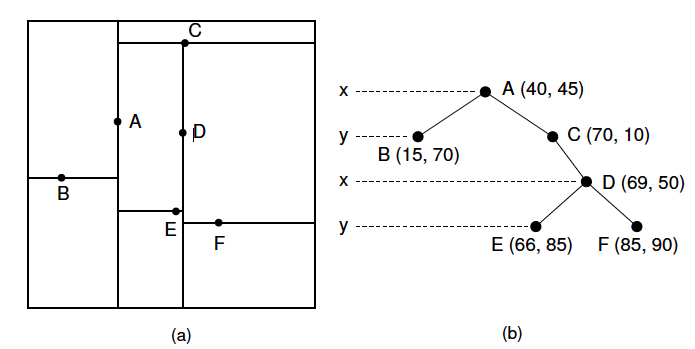
构建
KD树构建的过程就是迭代二分空间的过程
经典算法:
选择方差最大的维度,计算中位数点,作为划分点,分为左右子树,迭代上述过程, 直到空间上的点小于阈值
检索
因为ANN这个任务并不像关系数据库中那样需要精准的结果,而是得到其中Top-K的候选结果返回。
KD树的检索过程其实就是一个二叉树的回溯搜索过程:
- 根据目标p的坐标和kd树的结点向下进行搜索,如果树的结点root是以数据集的维度d以来切分的,那么如果p的维度d坐标值小于root,则走左子结点,否则走右子结点。
- 到达叶子结点时,将其标记为已访问。如果S中不足k个点,则将该结点加入到S中;否则如果S不空且当前结点与p点的距离小于S中最长的距离,则用当前结点替换S中离p最远的点。
- 如果当前结点不是根节点,执行(a);否则,结束算法。
a. 回退到当前结点的父结点,此时的结点为当前结点(回退之后的结点)。将当前结点标记为已访问,执行(b)和(c);如果当前结点已经被访过,再次执行(a)。
b. 如果此时S中不足k个点,则将当前结点加入到S中;如果S中已有k个点,且当前结点与p点的距离小于S中最长距离,则用当前结点替换S中距离最远的点。
c. 计算p点和当前结点切分线的距离。如果该距离大于等于S中距离p最远的距离并且S中已有k个点,执行步骤3;如果该距离小于S中最远的距离或S中没有k个点,从当前结点的另一子节点开始执行步骤1;如果当前结点没有另一子结点,执行步骤3。
LSH
LSH即 local sensitive hash,局部敏感哈希。不同于sha256、MD5这种避免碰撞的函数,这里我们选取hash函数的时候希望语义相近的向量可以映射到同一个桶里。这里有一个前提在的:
原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。
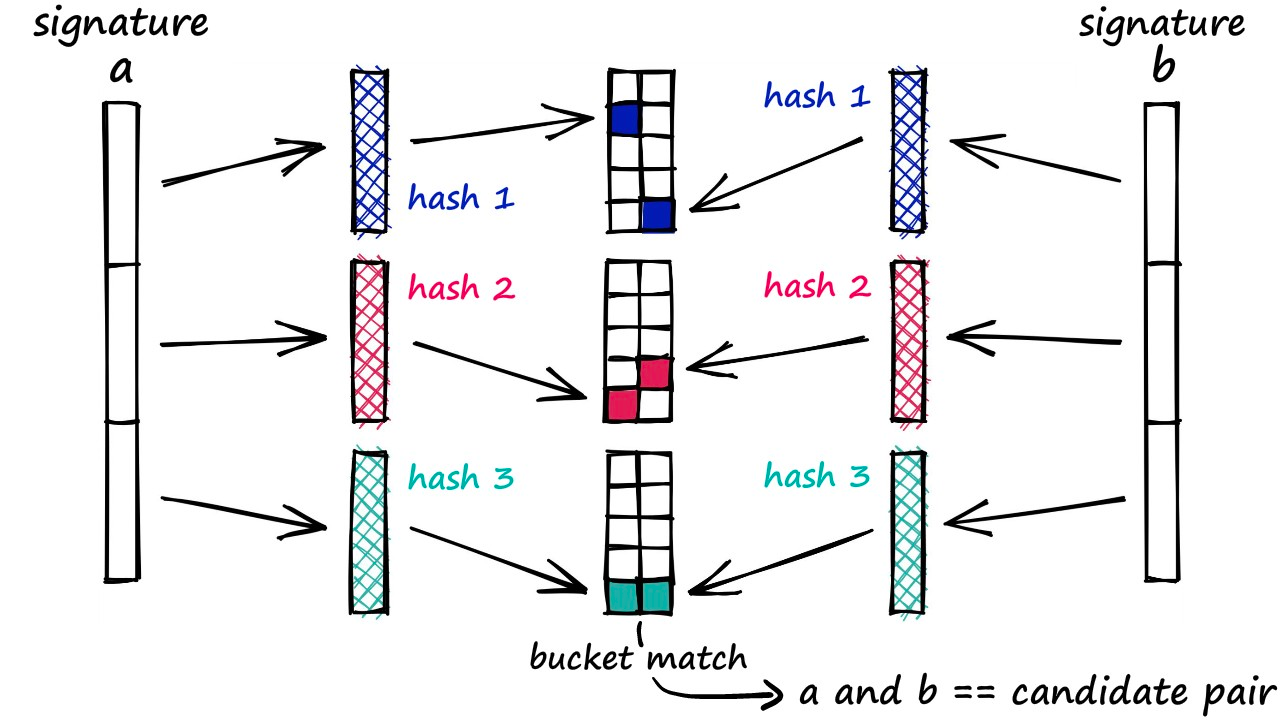
构建
- 选取一组的LSH hash functions;
- 将所有数据经过 LSH hash function 哈希到相应的hash码,所有hash数据构成了一个hash table;
检索
- 将查询数据经过LSH hash function哈希得到相应的编码;
- 通过hamming 距离计算query数据与底库数据的距离,返回最近邻的数据
当然也有其他的实现方案,这里不一一列举了。
量化
LSH这一类算法给了一个很好的加速方案,既然在原始向量空间内存在计算慢的问题,那么把向量数据映射到一个新的空间是不是就可以加速了。量化的算法就是这么想的,float型数据内存占用大,计算慢,那映射到整型数据就快了。
PQ量化
PQ量化,即乘积量化,这里的乘积指的是笛卡尔积。
如图所示。我们有一个向量库,里面有N个向量,每个向量D维。简要介绍一下算法原理:
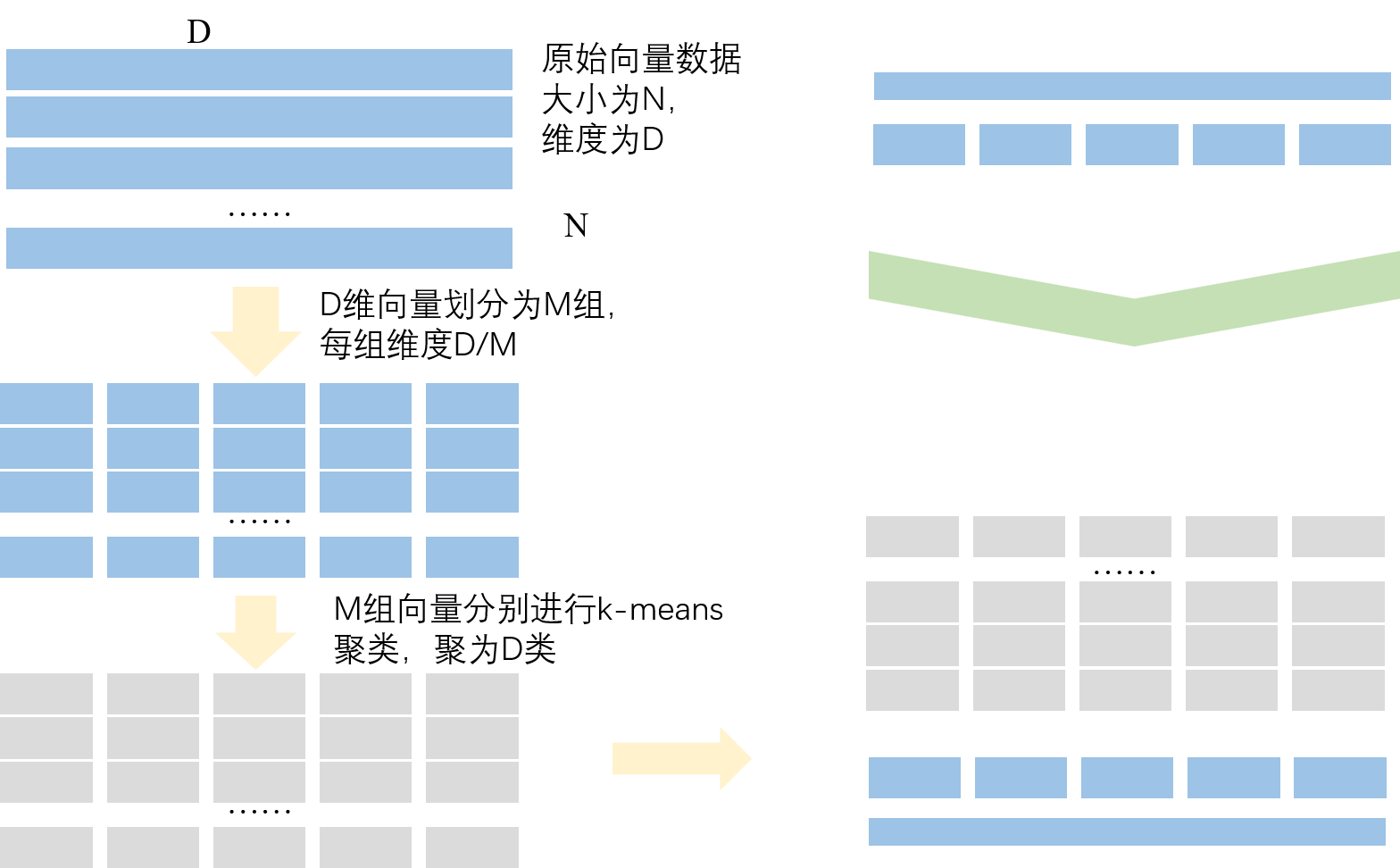
PQ 量化一般分为三个步骤:
Train
- 向量切分:将D维向量切分成M组子向量,每个子向量 $\frac{D}{M}$ 维。
- 聚类:分别在每一组子向量集合内,做Kmeans聚类,在每个子向量空间中,产生K个聚类中心。
- 每个聚类中心就是一个 $\frac{D}{M}$ 维子向量,由一个id来表示,叫做clusterid。
- 一个子空间中所有的clusterid,构造了一个属于当前子空间的codebook。对于当前向量库,就有M个codebook。
- 这M个codebook所能表示的样本量级就是 $K^M$,也就是 M个codebook的笛卡尔积。
建库
对于子向量空间中的N个子向量样本,在完成Kmeans聚类之后,用这个聚类中心的clusterid来代表这个子向量。这就是构建底库的过程。
原本我们的向量库的大小为 $N\times D\times 32bit$,压缩后,clusterid按照8bit来算的话,那就是 $N\times M * 8bit $,相比压缩前少了很多。
查找
这里查找的过程存在两种方式:SDC和ADC
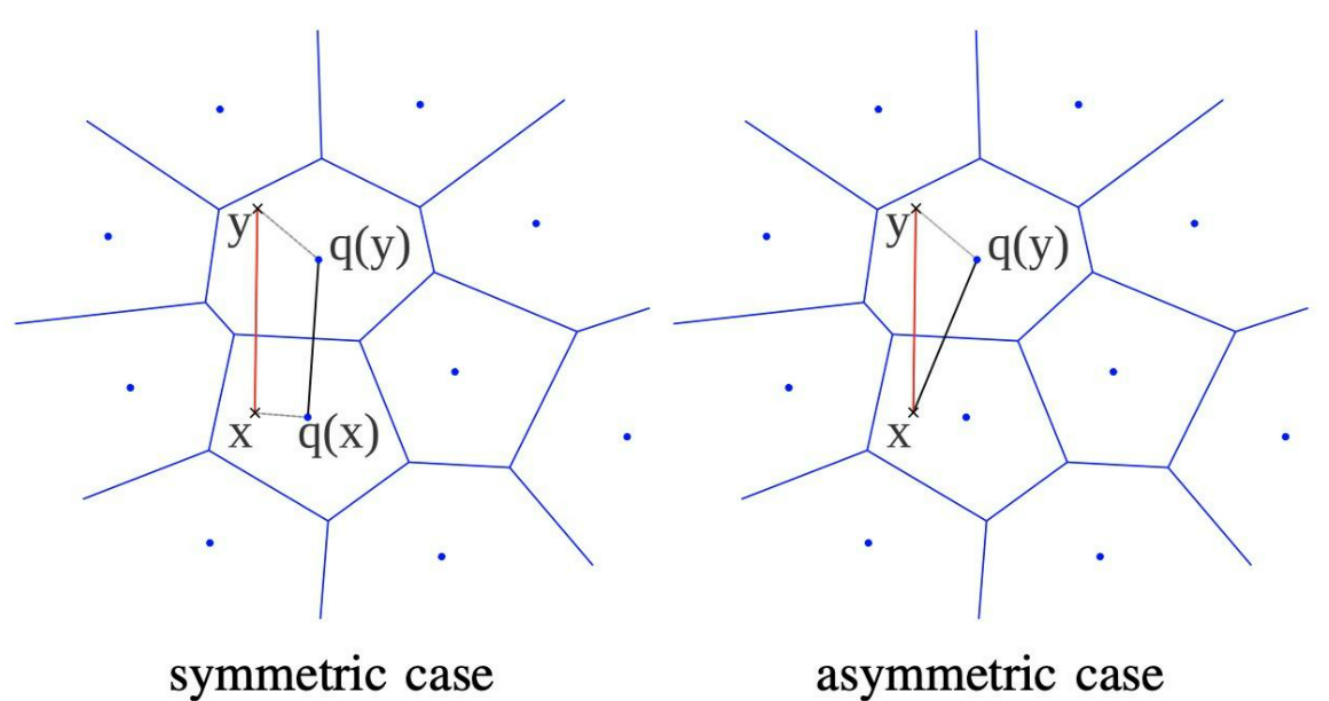
SDC
S=symmetric,对称的。如图symmetric case。图中x就是query检索向量,y就是向量库里面的向量(注意,y已经是量化过了的,就是上文中说的那个用数字id替代向量)。那么如何计算x与y的距离呢?
- 首先,计算q(x),拿到x对应的聚类中心;同样的,计算q(y),拿到y对应的聚类中心。
- q(x)和q(y)就是两个完整的子向量,我们计算这两个向量的距离,便是当前子空间下的距离。
为什么名字叫symmetric呢?因为他俩都是用对应的聚类中心来计算距离,所以是对称的。
优点:
- 两两聚类中心之间的距离,可以离线就计算好,在线直接查表,提升了在线query的效率。
缺点:
- 误差也比ADC来的大,因为有x和q(x),y和q(y)两个量化误差。
ADC
A=asymmetric,不对称的。上文中讲了对称是因为SDC都用了对应的聚类中心。那么ADC,就只有向量库中的y使用了聚类中心,而query向量x没有。那么,计算距离的时候,计算的就是x和q(y)的距离了。ADC的精确度更高,因为只有y和q(y)这一个量化误差;当然必须要在线计算(x是用户请求带过来的),计算速度不如SDC。
计算过程
将每一个子空间下的所有距离的平方相加再开根号,就是最终的X跟Y的距离了(就是使用每个子空间的向量距离进行了一次欧氏距离计算)。
SQ量化
SQ量化,又叫标量量化。是按照向量维度统计min-max最值,然后将每一维向量归一化指定bit数整数的量化方式。
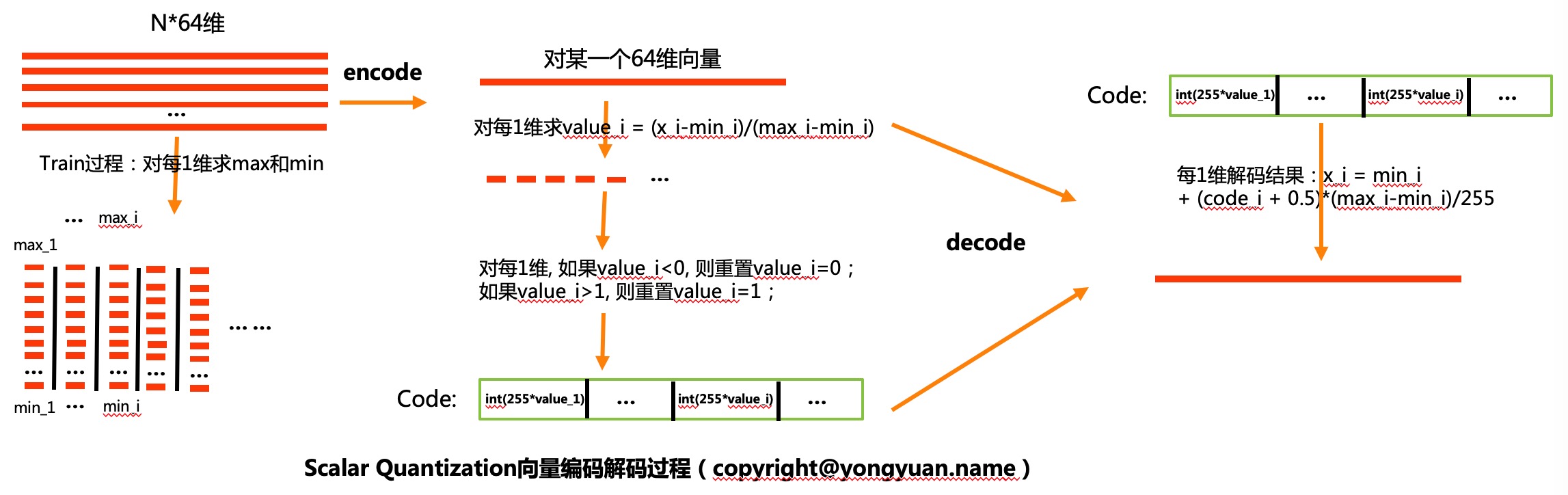
基本原理如上图所示。
IVF类方法
上面讲的量化算法,仅仅并没有解决全库计算的问题,虽然数据上做了压缩,如果数据量一大,计算量还是很大。如果可以只计算最相关的一部分,是不是就可以进一步减少了呢。这就是IVF算法的思路。
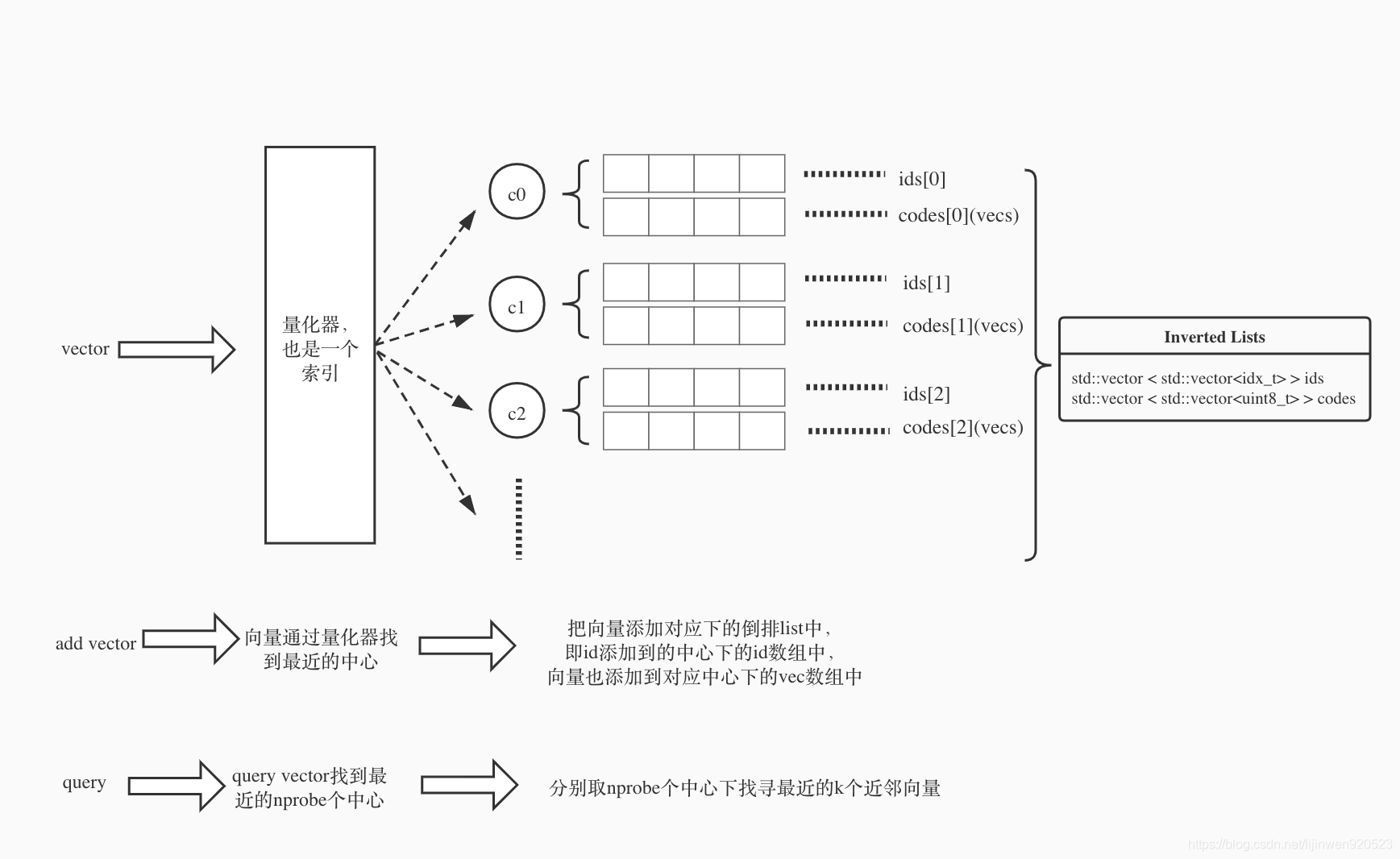
概括一下:
IVF主要利用倒排的思想保存每个聚类中心下的向量(id,vector),每次查询向量的时候找到最近的几个中心,分别搜索这几个中心下的向量。通过减小搜索范围,大大提升搜索效率。
这里额外补充一点:
- IVF跟PQ结合的时候,IVF的聚类中心里面向量按照PQ量化的聚类时,我们将不会在样本上直接做PQ量化,而是对样本Y和聚类中心q(Y)的残差向量(向量减法,Y-q(Y))做PQ量化。
基于图的方法
让我们重新回顾一下ANN这个任务:

已有的向量数据库内容就是图中的点,ANN的任务就是对给定一个点找到距离最近的点。那么如果每个点都知道离自己近的点,那么是不是就可以沿着这个连接线找到相近的点了。这样就避免了与所有数据计算距离。这就是基于图算法出发点。
NSW
NSW(navigate small world),漫游小世界算法。对于每个新的传入元素,我们从结构中找到其最近邻居的集合(近似的 Delaunay 图, 就是上面的右图)。该集合连接到元素。随着越来越多的元素被插入到结构中,以前用作短距离边现在变成长距离边,形成可导航的小世界。
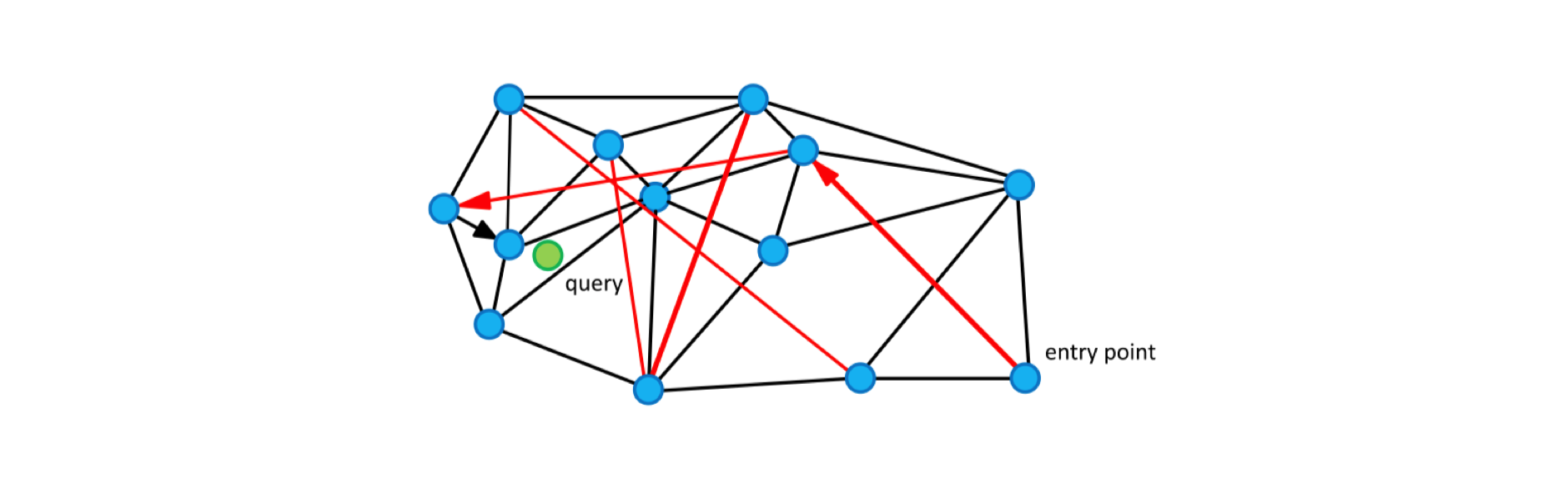
圆(顶点)是度量空间中的数据,黑边是近似的 Delaunay 图,红边是用于对数缩放的长距离边。箭头显示从入口点到查询的贪心算法的示例路径(显示为绿色)。
图中的边有两个不同的目的:
- Short-range edges,用作贪婪搜索算法所需的近似 Delaunay 图。
- Long-range edges,用于贪婪搜索的对数缩放。负责构造图形的可导航小世界(NSW)属性。
NSW查找步骤
- 随机选一个点作为初始进入点,建立空废弃表g和动态列表c,g是变长的列表,c是定长为s的列表(s>m),将初始点放入动态列表c(附上初始点和待查找q的距离信息),制作动态列表的影子列表c’。
- 对动态列表c中的所有点并行找出其“友点”,查看这些“友点”是否存储在废弃表g中,如果存在,则丢弃,如不存在,将这些 剩余“友点”记录在废弃列表g中(以免后续重复查找,走冤枉路)。
- 并行计算这些剩余“友点”距离待查找点q的距离,将这些点及其各自的距离信息放入c。
- 对动态列表c去重,然后按距离排序(升序),储存前s个点及其距离信息。
- 查看动态列表c和c’是否一样,如果一样,结束本次查找,返回动态列表中前m个结果。如果不一样,将c’的内容更新为c的 内容,执行第2步。
NSW有什么问题呢:
- 先插入的点构建的边,大都是长边;后插入的大都是短边。边的的连接关系不是很均衡。实际搜索的时候优化空间还比较大。
HNSW
HNSW(Hierarchical Navigable Small World)是对 NSW 的一种改进。HNSW 借鉴了跳表的思想,根据连接的长度(距离)将连接划分为不同的层,然后就可以在多层图中进行搜索。在这种结构中,搜索从较长的连接(上层)开始,贪婪地遍历所有元素直到达到局部最小值,之后再切换到较短的连接(下层),然后重复该过程,如下图所示:
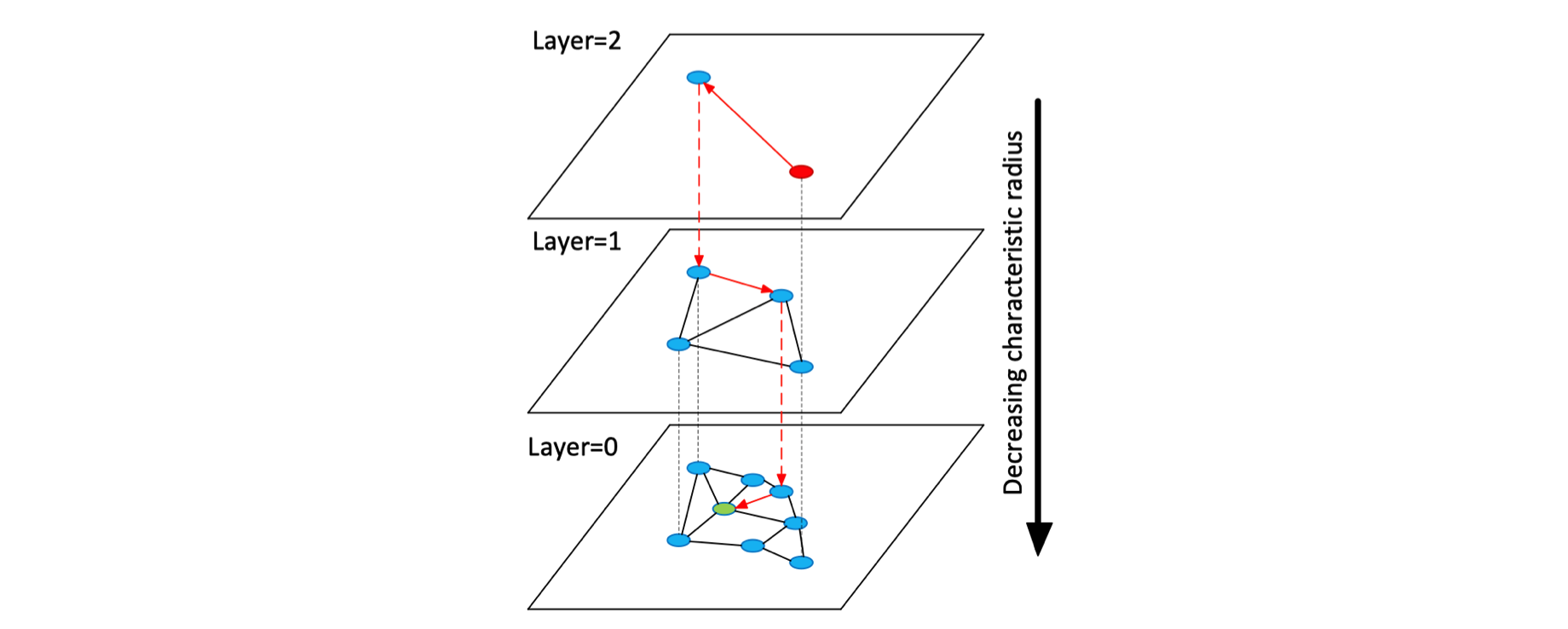
利用这种结构可以将原来 NSW 的多重对数(Polylogarithmic)计算复杂度降低至对数(Logarithmic)复杂度。
本文标题:从向量数据库到 ANN search
文章作者:王二
发布时间:2023-09-10
最后更新:2024-11-06
原始链接:https://wanger-sjtu.github.io/ANN-algo/
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!