VectorizeLoop这个PASS就是对标记为ForKind::kVectorized的For循环做向量化处理,并对For循环中的语句涉及到的变量,替换为Ramp,以便于在Codegen的过程中生成相关的向量化运算的指令。
VectorizeLoop这个PASS的入口函数如下,只有在打开enable_vectorize=true的情况下载才会被启用,否则VectorizeSkipper会把ForKind::kVectorized的For循环替换为普通循环。
1
2
3
4
5
6
7
8
9
10
11
12
| Pass VectorizeLoop(bool enable_vectorize) {
auto pass_func = [=](PrimFunc f, IRModule m, PassContext ctx) {
auto* n = f.CopyOnWrite();
if (enable_vectorize) {
n->body = LoopVectorizer()(std::move(n->body));
} else {
n->body = VectorizeSkipper()(std::move(n->body));
}
return f;
};
return CreatePrimFuncPass(pass_func, 0, "tir.VectorizeLoop", {});
}
|
下面就以UT中的几个例子,介绍一下源码实现。
vectorize_loop
1
2
3
4
5
6
7
8
9
10
11
12
| dtype = "int64"
n = te.var("n")
ib = tvm.tir.ir_builder.create()
A = ib.pointer("float32", name="A")
with ib.for_range(0, n) as i:
with ib.for_range(0, 4, kind="vectorize") as j:
A[i*4+j] += tvm.tir.const(1, A.dtype)
stmt = ib.get()
assert isinstance(stmt.body, tvm.tir.For)
mod = tvm.IRModule.from_expr(tvm.tir.PrimFunc([A, n], stmt))
stmt = tvm.tir.transform.VectorizeLoop()(mod)["main"].body
|
上面的这个代码完成的是,向量加法,长度为4n的向量A,对每个元素+1。
1
2
3
4
5
6
7
8
9
10
|
for (i, 0, n) {
vectorized (j, 0, 4) {
A[((i*4) + j)] = (A[((i*4) + j)] + 1f)
}
}
for (i, 0, n) {
A[ramp((i*4), 1, 4)] = (A[ramp((i*4), 1, 4)] + x4(1f))
}
|
可以看到在经过VectorizeLoop的PASS以后,内层的循环消掉了,替换成为了一个Ramp的向量指令,这个在CPU中会被替换为SIMD指令(neon,AVX等)
PASS流程
在向量化的处理的PASS中是在LoopVectorizer中处理的,处理For循环部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class LoopVectorizer : public StmtMutator {
public:
Stmt VisitStmt_(const ForNode* op) final {
if (op->kind == ForKind::kVectorized) {
ICHECK(is_zero(op->min));
auto* extent_as_int = op->extent.as<IntImmNode>();
if (!extent_as_int || extent_as_int->value < 1) {
LOG(FATAL) << "Failed to vectorize loop with extent " << op->extent;
}
return Vectorizer(op->loop_var, static_cast<int>(extent_as_int->value))(op->body);
} else {
return StmtMutator::VisitStmt_(op);
}
}
};
|
当遇到需要向量化的节点时,首先记录循环变量和范围,这个在后续替换相应的Load和Store操作为Ramp时用到。然后就到了Vectorizer部分,遍历For循环体,修改相应的stmt。
1
2
3
| Vectorizer(Var var, int var_lanes) : var_(var), var_lanes_(var_lanes) {
ramp_ = Ramp(0, 1, var_lanes);
}
|
在Vectorizer中对不同的PrimExpr、Stmt做了重载。这里不逐一介绍,就以上面的向量加计算,介绍一下用到的函数以及流程。
首先看一下这里的上面sch的For的循环内的计算逻辑:
1
| A[((i*4) + j)] = (A[((i*4) + j)] + 1f)
|
因为TVM中,Stmt的表达可以视为一个DSL的语言,访问的时候也是按照深度优先的策略遍历的AST,这里把上面的计算过程简单表示为一个AST的语法树,然后再分析一下流程中调用的各个函数是如何处理的。
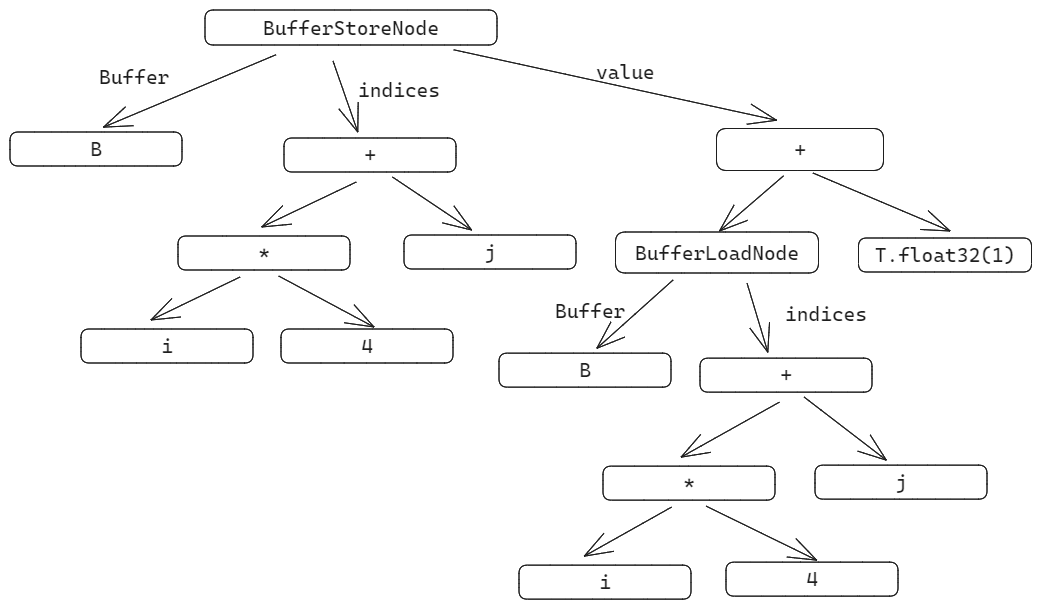
从上面的AST的示意图可以看出来,对于上面的sch,依次访问了BufferStoreNode、Add Mul、BufferLoadNode 等。这里就以这几个Node的处理介绍一下向量化的过程。
所谓向量化的过程就是把这个标记为kVectorized的标量循环操作映射到向量化的操作,对于上面的例子来说就是把所有关于j的访问映射为RampNode,以便于后续处理可以正确生成相应的指令。
BufferStoreNode
BufferStoreNode中有三部分:
- buffer——写入的buffer
- value——待写入的值或者表达式
- indices——写入buffer的坐标
这里的目的就是修改value和indices中的内容。
对于indices,是在这里完成的。最终通过MapHelper依次访问了indices的表达式。
1
2
| auto fmutate = [this](const PrimExpr& index) { return this->VisitExpr(index); };
Array<PrimExpr> indices = op->indices.Map(fmutate);
|
对于value 则是直接遍历。
1
| PrimExpr value = this->VisitExpr(op->value);
|
AddNode
对于AddNode和SubNode 都会走到AddSubVec这个模板函数。
这个函数里面首先会遍历左右表达式,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| PrimExpr a = this->VisitExpr(op->a);
PrimExpr b = this->VisitExpr(op->b);
if (a.same_as(op->a) && b.same_as(op->b)) {
return GetRef<PrimExpr>(op);
} else {
int lanes = std::max(a.dtype().lanes(), b.dtype().lanes());
if (lanes != 1) {
const RampNode* b_ramp = b.as<RampNode>();
const RampNode* a_ramp = a.as<RampNode>();
if (a.dtype().lanes() == 1 && b_ramp) {
return Ramp(fcompute(a, b_ramp->base),
fcompute(make_zero(b_ramp->stride.dtype()), b_ramp->stride), b_ramp->lanes);
}
if (b.dtype().lanes() == 1 && a_ramp) {
return Ramp(fcompute(a_ramp->base, b), a_ramp->stride, a_ramp->lanes);
}
}
return fcompute(BroadcastTo(a, lanes), BroadcastTo(b, lanes));
|
如果遍历之后没有变化,就直接返回了。而对于这里的我们需要计算的是
j 是需要向量化的坐标。i*4 是没有变化的。遍历以后a没变化,b变成了T.Ramp(0, 1, 4) 这时候lanes=4,会走到第一个if分支,返回的是新构造的RampNode
其他的分支也类似。比如:
1
2
3
| A[i * 4 + j] + T.float32(1)
A[i * 4:i * 4 + 4] T.float32(1)
|
这里会把a、b broadcast为一个向量再做计算。
VarNode
对于这里的VarNode判断就比较简单了,如果匹配到的是需要向量化的变量,就返回构造函数中构造的RampNode,否则就返回。其他的操作,暂时略过。
1
2
3
4
5
6
7
8
| Var var = GetRef<Var>(op);
if (var.same_as(var_)) {
return ramp_;
}
else {
return std::move(var);
}
|
MulNode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| PrimExpr a = this->VisitExpr(op->a);
PrimExpr b = this->VisitExpr(op->b);
if (a.same_as(op->a) && b.same_as(op->b)) {
return GetRef<PrimExpr>(op);
} else {
int lanes = std::max(a.dtype().lanes(), b.dtype().lanes());
if (lanes != 1) {
const RampNode* b_ramp = b.as<RampNode>();
const RampNode* a_ramp = a.as<RampNode>();
if (a_ramp && b.dtype().lanes() == 1 && analyzer_.CanProve(b > 0)) {
return Ramp(a_ramp->base * b, a_ramp->stride * b, a_ramp->lanes);
}
if (b_ramp && a.dtype().lanes() == 1 && analyzer_.CanProve(a > 0)) {
return Ramp(b_ramp->base * a, b_ramp->stride * a, b_ramp->lanes);
}
}
return Mul(BroadcastTo(a, lanes), BroadcastTo(b, lanes));
}
return BinaryVec<Mul>(op);
|
这里的处理逻辑与Add基本一致。只是在计算RampNode的时候有点区别。
本文标题:TVM 源码阅读PASS — VectorizeLoop
文章作者:王二
发布时间:2023-09-09
最后更新:2024-11-06
原始链接:https://wanger-sjtu.github.io/VectorizeLoop/
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!