作者: Jiayi Weng(EnvPool 作者)
原文: https://trinkle23897.github.io/learning-beyond-gradients/
核心观点: 规则系统 + Coding Agent = 持续学习的 新范式
背景
作者在维护 EnvPool 时思考一个问题:能否用规则策略代替神经网络来测试游戏环境是否正确运行?
他用 Codex (gpt-5.4) 编写纯规则策略,结果远超预期:
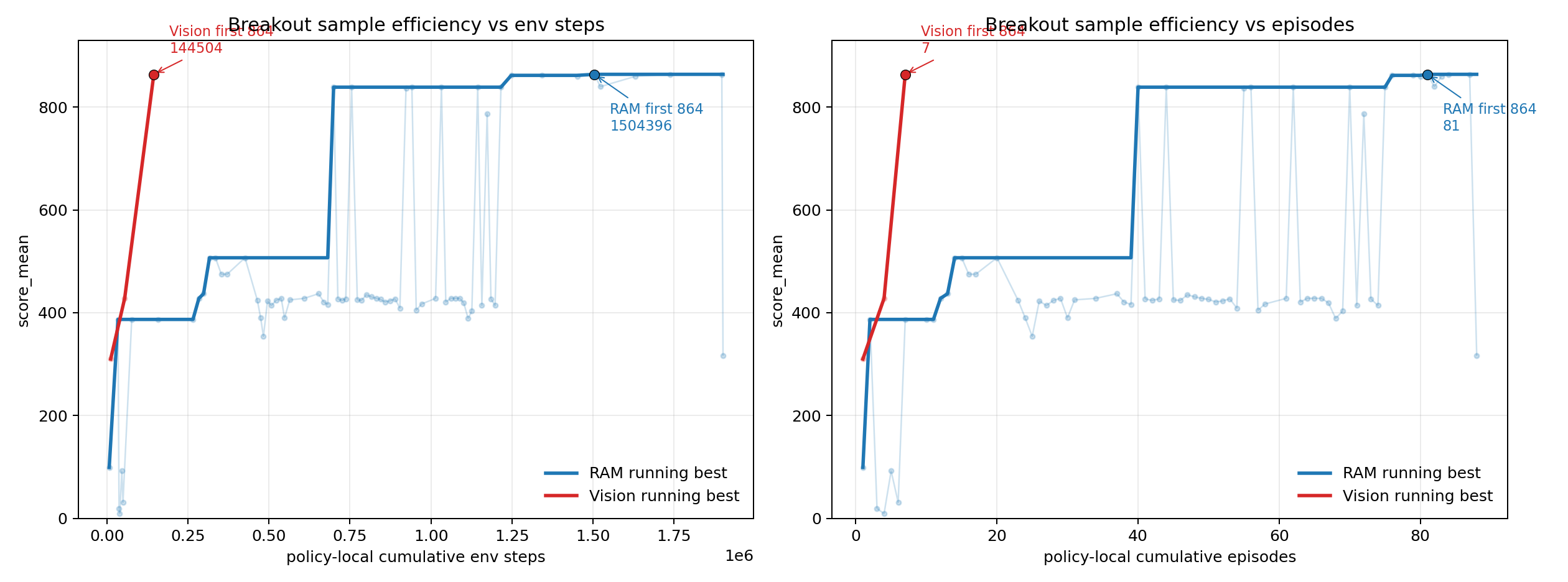
- Atari Breakout: 387 → 507 → 839 → 864(理论最高分)
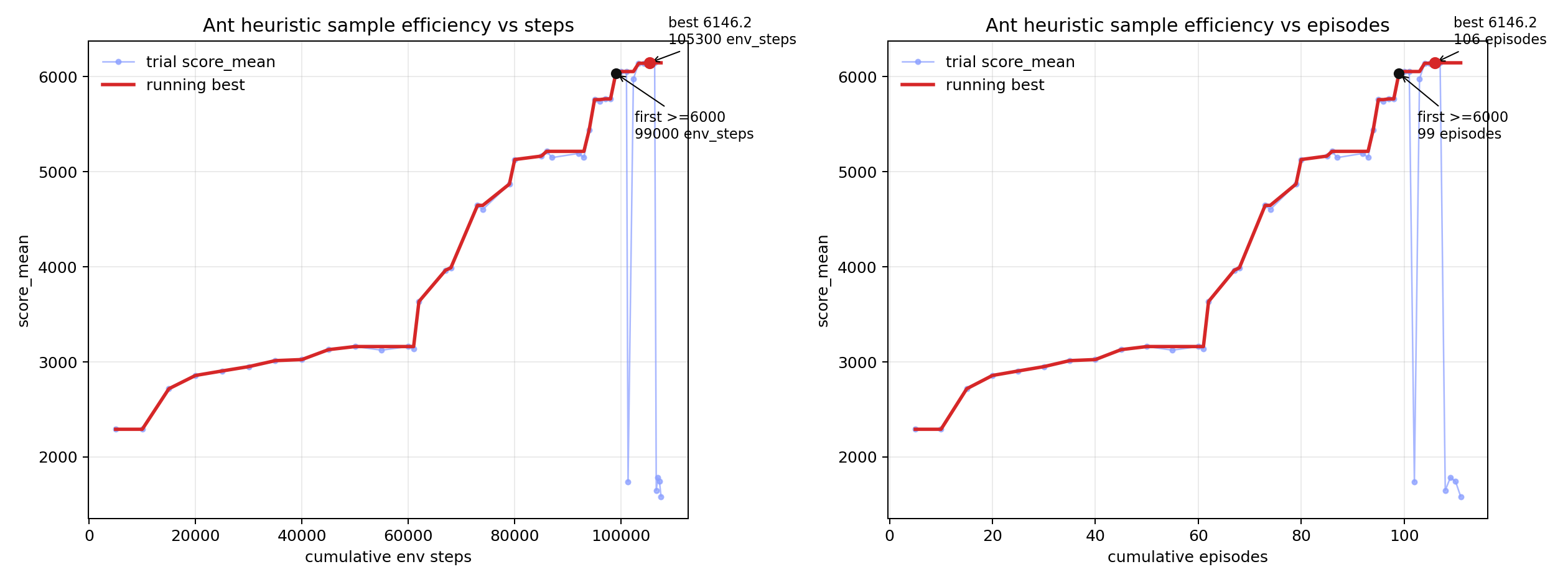
- MuJoCo Ant: 纯 Python 策略达到 6000+(对标常见 Deep RL)
- MuJoCo HalfCheetah: 规则 + 在线规划达到 11836.7
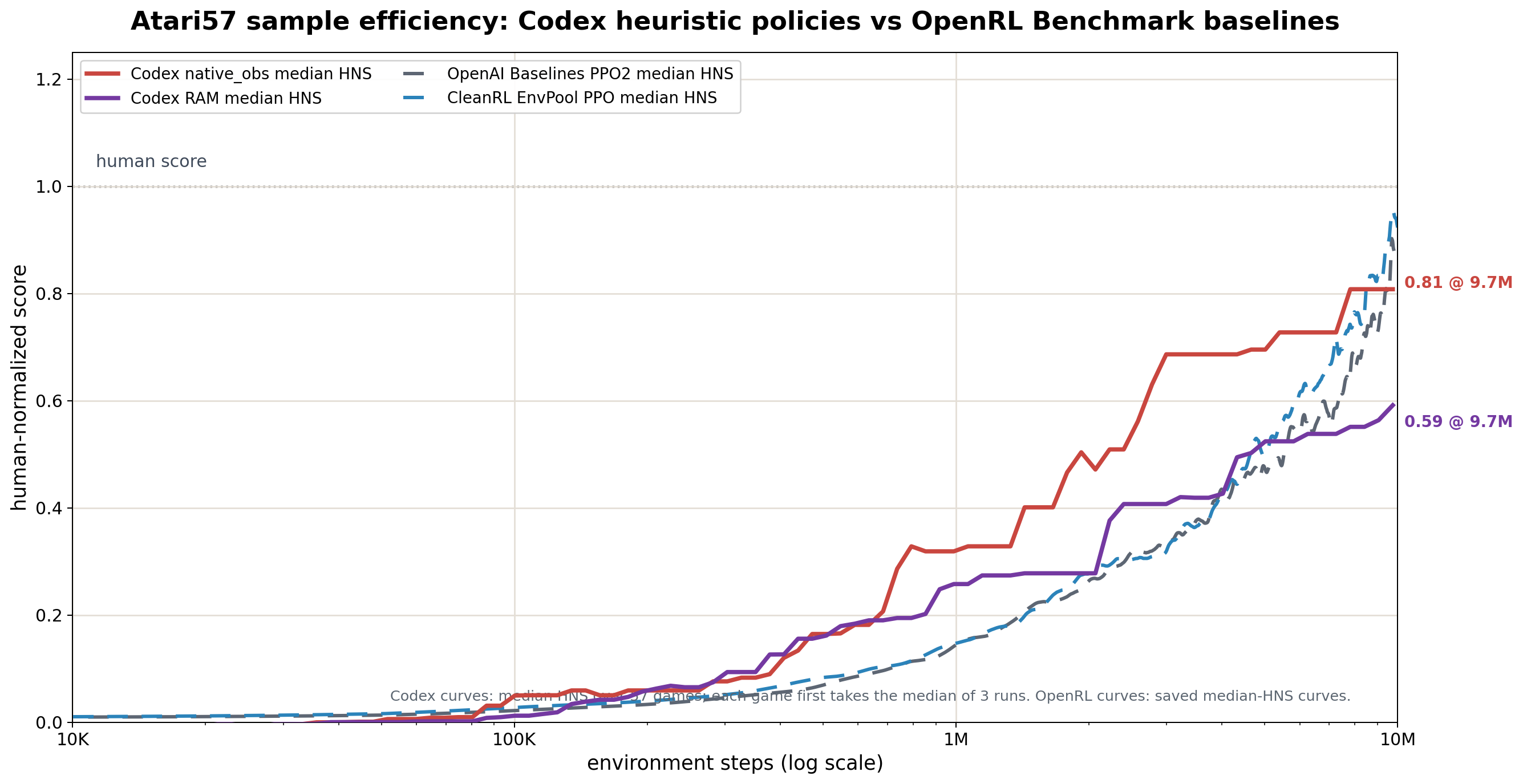
- Atari57(57游戏 × 2模式 × 3重复): 中位数 HNS 远超同期 PPO
关键发现:Codex 没有训练神经网络,而是维护一个可以持续增长的软件系统。
核心概念:Heuristic Learning(HL)
| 维度 | Deep RL | Heuristic Learning |
|---|---|---|
| 策略 | 神经网络参数 | 代码:规则、状态机、控制器、MPC |
| 状态 | 观测向量 | 可读变量、检测器、缓存 |
| 更新 | 梯度反传 | Coding Agent 直接编辑代码 |
| 记忆 | Replay Buffer | 显式存储试验记录、失败原因 |
HL 的优势:
- 可解释性:规则可以直接翻译成自然语言
- 样本效率:一次有效代码更新可以直接跳到新策略
- 可回归测试:旧能力变成测试用例、回放、Golden Case
- 避免灾难性遗忘:旧能力不只存在权重里,也可以写在规则和测试里
为什么以前没成?
专家系统的问题是:维护成本太高。
今天加一条规则修 A,明天 B 坏了,后天再加一条 if-statement,大后天没人敢删任何东西了。
人类维护规则就像工业革命前纺纱——一个人能做,但规模一大,成本就爆炸了。Coding Agent 改变了这个维护曲线。
Continual Learning 的新思路
HL 也会遗忘,只是形式不同:
- 新规则修了旧场景
- 新记忆把 agent 导向错误方向
- 测试太窄,策略学会作弊
所以 HL 的持续学习需要两个操作:
- 吸收反馈:把新失败写回系统
- 压缩历史:把本地补丁折叠成更简单的表示
一个只增长不压缩的 HS 最终会变成一个大泥球——记得很多,但没人敢碰,系统逐渐腐化。
这把 Continual Learning 从”怎么更新参数”变成了”怎么维护一个持续吸收反馈的软件系统”。
耦合复杂度
作者定义了耦合复杂度(coupling complexity):一个 Coding Agent 为了支持 HL 能维护的策略复杂度。
- 模块化把全局耦合切成局部耦合,降低复杂度
- 测试让 Agent 不需要每次在脑子里模拟整个系统
- 更强的模型能同时处理更多交互
- 更长的上下文意味着更少丢失的线索
下一个范式?
当前范式演进:Pretraining → RLHF → 大规模 RL/RLVR。任何可以验证的东西都开始变得可解。
HL 的局限性:受限于代码能表达的东西,特别是复杂感知和长时泛化。
最有前景的方向:用 HL 快速处理在线数据,把在线经验转化为可训练、可回归测试、可过滤的数据,然后周期性更新神经网络。
机器人场景的 System 1 / System 2 分工:
- 浅层 NN:System 1,负责感知、分类、目标状态估计
- HL:System 1,负责新鲜数据处理、规则、测试、回放、记忆、安全边界
- LLM Agent:System 2,给 HL 反馈,改进数据,周期性提取 HL 生成的数据来更新自己
实验数据
Atari Breakout 样本效率
MuJoCo Ant 样本效率
Atari57 对比
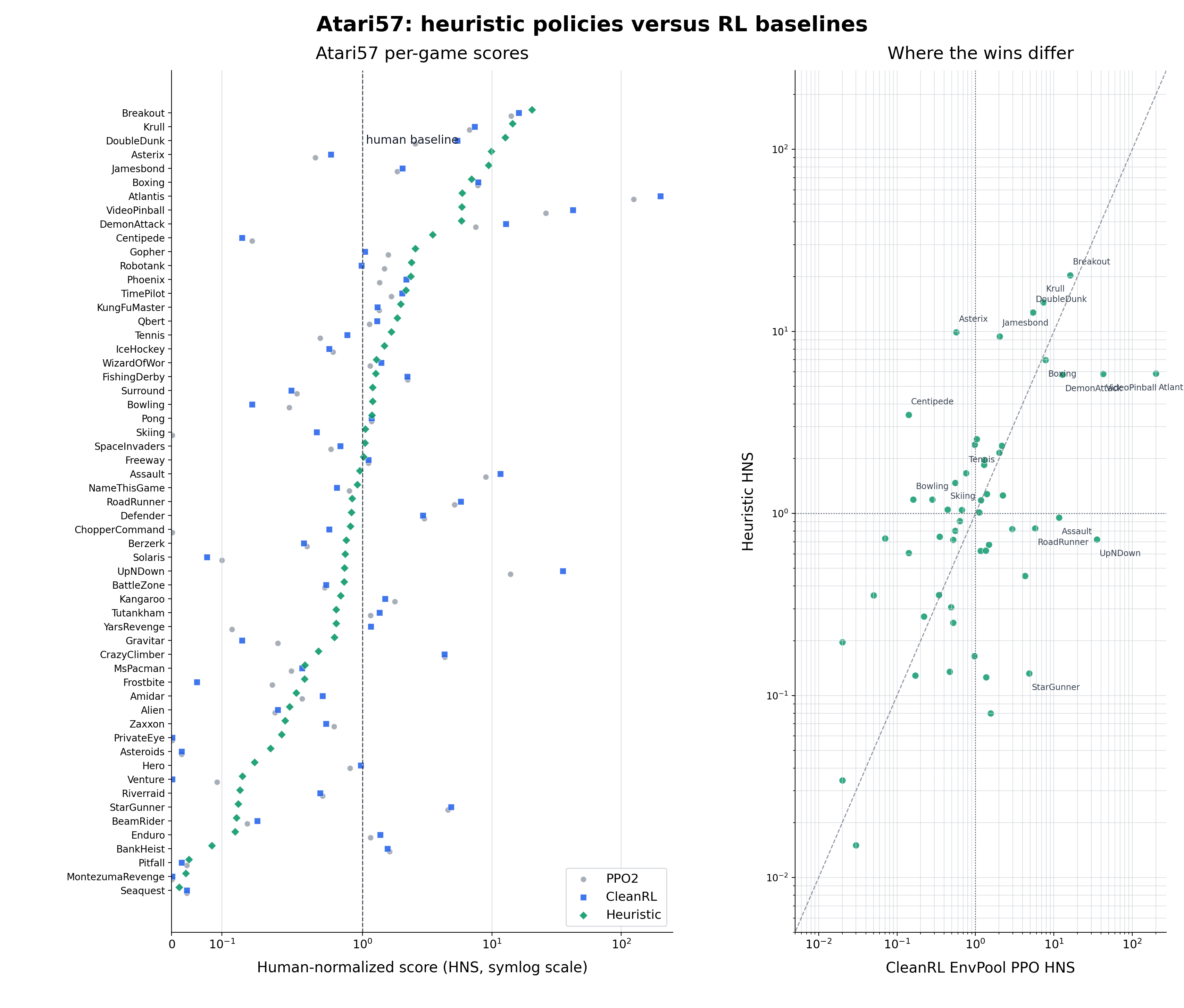
实验代码和更多细节:https://github.com/Trinkle23897/learning-beyond-gradients