本文覆盖推理场景的 7 种并行策略:TP、PP、DP、EP、DP Attention、SP、CP。
按切分维度分为四组:
Weight(参数维度):TP、EP
Batch(样本维度):DP、DP Attention
Sequence / Context(序列维度):SP、CP
Layer(深度维度):PP
每章围绕”切什么、在哪里通信、什么时候用”讲,配一张对应配置的完整流程图。
本文基于 SGLang / vLLM 截至 2026-05-05 的代码状态整理,引用的代码可能随版本迭代漂移,阅读时请以当前仓库代码为准。通信量、显存、延迟等数字是配置相关的估算,用于量级判断,不代表具体部署的实测结果;生产选型请以自己的基准测试为准。作者能力有限,如发现事实错误、理解偏差或与代码不一致处,欢迎指正。
0. 为什么需要并行
单卡放不下或算不动模型时,把”某个东西”切到多卡。推理场景选策略围绕三个目标:放得下(模型 + KV cache 进显存)、跑得快(prefill 吞吐 / decode 延迟)、通信不成瓶颈(尤其跨机)。
本文按从简单到复杂的顺序讲 7 种策略,每章配一张对应配置的完整流程图:
| 策略 | 切什么 | 解决什么问题 | |
|---|---|---|---|
| §1 | TP | Weight 的 hidden 维 | 单层算不动 / 放不下 |
| §2 | PP | Layer(深度) | 整模型放不下(跨机) |
| §3 | DP | Batch(请求复制) | 扩吞吐(外层并行) |
| §4 | EP | MoE Expert | 超大 MoE 模型(专家切卡) |
| §5 | DP Attention | Batch + attention heads 的小组切 | MoE 跨机时解耦 attention 和 MoE |
| §6 | SP | Sequence(TP 区外激活) | 省 TP 外的激活冗余显存 |
| §7 | CP | Sequence(attention 内部) | 超长 context(32K+) |
TP 和 EP 切参数,DP / DP Attention 切批次,SP / CP 切序列,PP 切深度——四个维度、互相正交、可以叠加。
1. TP(Tensor Parallelism,张量并行)
一句话:把权重矩阵按维度切到多卡,每卡只存/算一部分,出口处 AllReduce 合并。
好处
- 权重、KV cache、TP 区域激活按 N 等分,线性降显存
- Prefill 阶段计算量也按 N 等分,扩算力
代价
- 每层 2 次 AllReduce(Attention 后 + MLP 后),对带宽极敏感
- 必须在 NVLink 域内(跨 IB 效率个位数),通常 TP ≤ 8
- Decode S=1 时 AllReduce 延迟主导
- TP > num_kv_heads 时要复制 KV head(KV cache 放大)
图解

图 1 TP=4 单机,H=8192,n_heads=64,S=2000,B=32
图 1 展示单层完整流程:① 输入 → ② QKV Proj → ③ Attention → ④ Output Proj → ⑤ AllReduce#1 → ⑥ LN + Residual → ⑦ MLP Up → ⑧ MLP Down → ⑨ AllReduce#2 → ⑩ 层输出。其中 ②⑦ 是列切、④⑧ 是行切、⑤⑨ 两次 AllReduce 合并 partial;①⑥⑩ 是每卡完整副本(TP 区域外的激活冗余,见 §6 SP)。
1.1 列切分 vs 行切分
TP 的所有操作归结为两种切法,两者配对使用,中间免通信,只在尾部 AllReduce 一次。
| 列切分(Column Parallel) | 行切分(Row Parallel) | |
|---|---|---|
| 切 W 的哪一维 | 输出维 [H, M] → [H, M/N] | 输入维 [M, H] → [M/N, H] |
| 每卡输入 | 完整副本 [S, H] | 已切分 [S, M/N](前一步列切的输出) |
| 每卡输出 | Y 的 1/N 列(已切分) | partial [S, H](4 份形状相同、需 Σ) |
| 通信 | ✓ 无 | ✗ 需 AllReduce |
规律:列切分输出切分,行切分输出 partial。列→行配对使用,只在块尾 AllReduce 一次。
在 Transformer 里的应用:
| 块 | 入口(列切) | 出口(行切 + AllReduce) |
|---|---|---|
| Attention | Wq/Wk/Wv [H,H] → [H,H/N] | Wo [H,H] → [H/N,H] + AR#1 |
| MLP | W1 [H,4H] → [H,4H/N] | W2 [4H,H] → [4H/N,H] + AR#2 |
| LayerNorm γ/β | 不切,每卡完整 | — |
图中 ② ⑦ 是列切(无通信),④ ⑧ 是行切(产 partial),⑤ ⑨ 是两次 AllReduce。
1.2 形状和显存(配置同图,B=32,S=2000,H=8192)
| 位置 | 无 TP | TP=4 每卡 |
|---|---|---|
| QKV 权重(每个) | [8192, 8192] = 128 MB | [8192, 2048] = 32 MB |
| Q/K/V reshape | [32, 2000, 64, 128] | [32, 2000, 16, 128] |
| Attention scores(③,Flash 不物化) | [32, 64, 2000, 2000] = 32 GB | [32, 16, 2000, 2000] = 8 GB |
| Wo 权重(④) | [8192, 8192] = 128 MB | [2048, 8192] = 32 MB |
| MLP W1(⑦) | [8192, 32768] = 512 MB | [8192, 8192] = 128 MB |
| MLP W2(⑧) | [32768, 8192] = 512 MB | [8192, 8192] = 128 MB |
| 单层权重合计 | ~1.5 GB | ~384 MB(÷4) |
三类激活:
- 🟦 橙色框内(②③④⑦⑧):每卡 1/N hidden,真正切分
- 🟧 蓝色框内(①⑥⑩):每卡完整副本——TP 区域外的冗余,SP 专治这个(见 §6)
1.3 通信量
每次 AllReduce(Ring) ≈ 2 × B × S × H × dtype × (N-1)/N
图里配置:≈ 2 × 32 × 2000 × 8192 × 2 × 3/4 ≈ 1.5 GB / 次
每层 2 次 ≈ 3 GB,80 层 ≈ 240 GB / 前向
Decode S=1 时每次通信缩到 ~800 KB——量小但次数多,延迟主导。这也是为什么 TP 组必须和 NVLink 域对齐:跨机 IB(~50 GB/s)下每次 AllReduce 从 2 ms 涨到 30 ms,80 层 160 次同步点爆炸。
1.4 GQA / MQA 下的 TP
标准 MHA 下 Q/K/V head 数相同。GQA 里 num_kv_heads < num_heads:
Llama 3: n_heads=64, n_kv_heads=8, TP=8
- Q: 每卡 8 heads
- K/V: 每卡 1 head
TP=16, n_kv_heads=8 → 每个 KV head 复制到 2 卡 ← KV cache 总量放大
选 TP size 时要权衡 KV 复制倍数。
2. PP(Pipeline Parallelism,流水线并行)
一句话:按 layer 把模型切到多卡,层内不切,只在 stage 边界 P2P 传一次激活——用最小通信换”装下超大模型”。
好处
- 通信量最小:只在 stage 边界 P2P 传一次激活,远小于 TP 的每层 AllReduce
- 跨机最友好:不依赖 NVLink,普通 IB / 以太网也能跑
- 把参数切到”深度”维度,单机装不下的超大模型首选维度
- Prefill 阶段 micro-batch 可流水填满,吞吐近 N×
代价
- 流水气泡:stage 串行依赖,首尾必有空等;靠 micro-batch 摊平,但 decode 难做大 M
- Decode 单请求延迟 = P 段之和:token 必须串行穿过所有 stage,PP 不降低延迟
- stage 切分需手工平衡:每段 FLOPs / 参数量接近才能填满流水
- 显存各 stage 不均衡(embedding、lm_head 偏重,KV cache 按层摊到各 stage)
图解
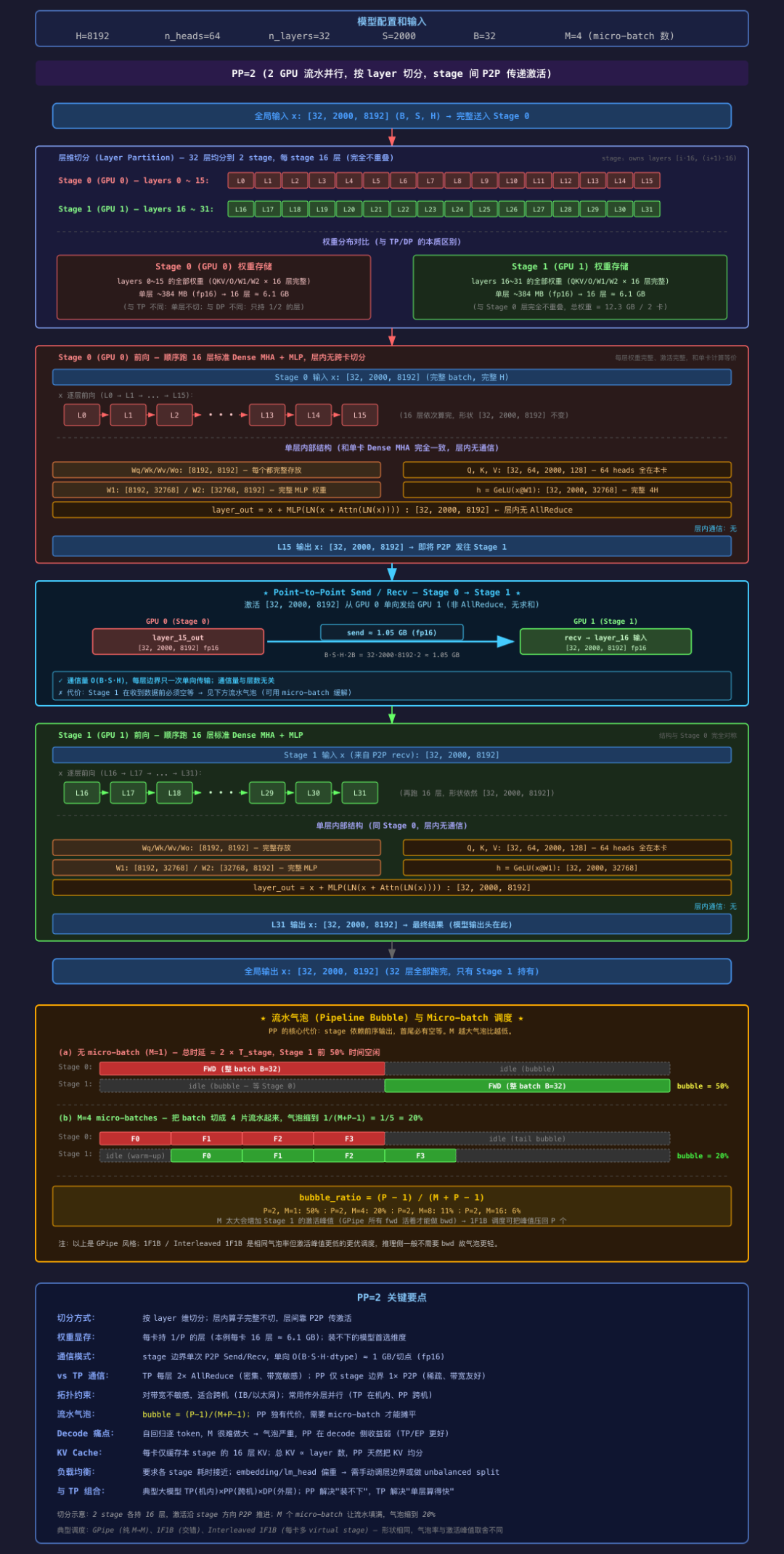
图 2 PP=2(32 层 Dense,H=8192,n_heads=64,B=32,S=2000,M=4 micro-batch)
2.1 切分方式:层切层不切
每层完整保留在单卡,切的是 layer 边界:
图 2 场景: n_layers=32, PP=2
- Stage 0 (GPU 0): layers [0..15]
- Stage 1 (GPU 1): layers [16..31]
和 TP / DP 对照:
| 维度 | 权重分布 | 每卡权重量 | 层内通信 | 层间通信 |
|---|---|---|---|---|
| TP | 每层切 H 维 | 1/N | 每层 2× AllReduce | 无 |
| DP | 每卡整模型 | 总参数 ×1 | 无 | 无 |
| PP | 每卡 1/P 层,层内完整 | 总参数 / P | 无 | P2P 一次 |
PP 的独特点:单层完整在一卡——每层内部 LN → Attn → LN → MLP 就是标准单卡 Dense kernel,没有 AllReduce / A2A / AG。
2.2 Stage 边界 P2P
唯一的跨卡通信:Stage 0 最末层的输出 → Stage 1 首层的输入。
GPU 0: L15 output [32, 2000, 8192]
↓ P2P Send (NCCL / Gloo,单向)
GPU 1: L16 input [32, 2000, 8192]通信量 ≈ B × S × H × dtype = 32 × 2000 × 8192 × 2 byte ≈ 1 GB(fp16),单向
每 stage 边界 1 次,与层数无关(对比 TP 每层 2× AllReduce)
带宽需求低,普通 IB / 以太网够用——跨机友好
2.3 流水气泡与 Micro-batch
stage 串行依赖带来的空等。图 2 底部对比两种调度:
| (a) M=1 | (b) M=4 (GPipe) |
|---|---|
| 时间 → 1 2 Stage 0 [===]空闲 Stage 1 空闲[===] |
时间 → 1 2 3 4 5 Stage 0 [m0][m1][m2][m3]空闲 Stage 1 空闲[m0][m1][m2][m3] |
| 总时延 2×T_stage, 气泡 50% | 总时延 5×T_stage, 气泡 20% |
气泡率:bubble_ratio = (P − 1) / (M + P − 1)
| (P,M) | 气泡 |
|---|---|
| (2, 1) | 50% |
| (2, 4) | 20% |
| (2, 16) | 6% |
| (4, 32) | 9% |
调度:推理(纯 forward)直接 GPipe 即可;1F1B / Interleaved 1F1B 主要优化训练的激活峰值,推理侧收益不大。
2.4 Prefill vs Decode 与典型组合
| Prefill | Decode | |
|---|---|---|
| 每步输入 | 整个 prompt(数百~数万 tokens) | 1 token per request |
| M 来源 | prompt 自然切 / 多 request 凑 | 只能靠并发请求数 |
| 气泡 | 小(M 大) | 大(M 小) |
| PP 价值 | 高,吞吐近 N× | 有限,单请求延迟 = P 段之和 |
PP 对 decode 不友好,decode 敏感场景保守用 P(P=2/4,不上 P=8+)。
典型组合(PP 几乎总是外层):
- 大密集模型(70B~405B): TP(机内) × PP(跨机) × DP(外层)
- MoE 模型: EP × TP × PP × DP
TP 在机内吃 NVLink,PP 跨机跑 IB,DP 扩吞吐——各司其职。
实用建议:
- 超大模型跨机:单机装不下(405B fp16 需 810 GB)时必选
- 连续批处理:多请求的不同 decode step 交错填流水,缓解 decode 气泡
- 负载均衡:embedding / lm_head 偏重 → 首/末 stage 做 unbalanced split(如首 stage 少 1 层)
3. DP(Data Parallelism,数据并行)
一句话:每卡复制完整模型权重,服务不同请求,前向零通信。和 TP/PP 切模型不同,DP 是”外层复制”——用来扩吞吐,不是用来”装下模型”。
好处
- 实现最简(SPMD,不切权重),跨机友好
- 吞吐 ×N 线性扩展,单请求延迟 = 单卡延迟
- 是 DP Attention 的”宿主维度”:dp_size > 1 才能开 DP Attention(见 §5)
代价
- 每卡放完整权重 + 完整 KV cache,N 卡总显存 = N × 单卡
- 单卡装不下模型时 DP 不能单独用,必须叠 TP/PP/EP
- 请求绑 rank,热/冷不均无法动态再平衡
图解

图 3 DP=4,每卡跑完整模型,互不通信
global batch B=32, DP=4:
GPU0: requests[0:8] ┐
GPU1: requests[8:16] │ 各卡看到 xᵢ [8, 2000, 8192], 跑完整模型
GPU2: requests[16:24] │ 前向零跨卡通信
GPU3: requests[24:32] ┘通信:推理前向跨 DP 零通信(训练反向有 gradient AllReduce,推理不存在)。
与其他策略组合时的跨 DP 通信(DP Attention / MoE EP A2A)是组合维度的代价,不属于纯 DP。
4. EP(Expert Parallelism,专家并行)
一句话:MoE 模型里把 256 个 expert 分到 N 卡,每 MoE 层 dispatch + combine 两次 A2A。
好处
- MoE 专家本来互相独立,按专家切零耦合
- 支撑巨大总参数量(DeepSeek-V3 671B 总 / 37B 激活)
- 通信规整(双向 A2A),可用 DeepEP 等 backend 深度优化
代价
- 每 MoE 层 2 次 A2A,跨机带宽敏感
- 负载不均:热门 expert 堆压某 rank → 需 capacity factor / EPLB
- 小 batch 低效:每卡进 expert 的 token 太少 GEMM 跑不满
- 只适用 MoE 模型
图解

图 4 —tp 4 —dp 4 —ep-size 4 —moe-a2a-backend deepep(不开 DP Attention)
4.1 副本结构
图 4 场景是 replica-level DP:16 卡切成 4 个独立模型副本,每副本 4 卡。
副本 0 (GPU 0-3) 副本 1 (GPU 4-7) 副本 2 (GPU 8-11) 副本 3 (GPU 12-15)
↑ TP=4 + EP=4 ↑ 同上 ↑ 同上 ↑ 同上
256 experts 分到 4 rank, 每 rank 64 experts副本间零通信,DataParallelController round-robin 分发请求
每副本内 attn_tp = tp_size = 4(不开 DP Attention 时 attention 用整个 TP world 切头),每副本输入 x: [8, 2000, 8192](B=32 / 4 副本 = 8 seq,副本内 4 卡 TP 广播这 8 seq)。
一层的走法:attention 段走 §1 TP 的”列切 + 行切 + AllReduce”模式,但出口的 AllReduce 换了一种走法——这是下面两节的重点。
4.2 Attention 出口:把 AllReduce 拆成 RS + AG
标准 TP 在 o_proj 后 AllReduce 一次合成完整 [16000, 8192],然后交给 MoE。问题:4 rank 每卡持完整 tokens → MoE dispatch A2A 发 4 倍冗余,浪费跨机带宽。
SGLang 用恒等式 AllReduce ≡ ReduceScatter + AllGather,把这次 AR 拆成两半,中间夹 MoE:
o_proj 出口 partial → [★ RS(attn_tp=4)] → MoE(dispatch/FFN/combine)→ [★ AG(attn_tp=4)] → 下一层
前半段,每 rank 留 1/4 tokens 后半段,拼回完整 tokensRS 后每 rank 只持 [4000, 8192] = 1⁄4 tokens,MoE dispatch 精确分发、零冗余
AG 后每 rank 拼回 [16000, 8192],下一层入口形状不变,直接接 QKV
数学上 RS + AG 等价 AllReduce,只是时间上拆开了,省下的是 MoE A2A 的 4× 冗余带宽。
前提:moe_a2a_backend ≠ none(deepep / mooncake 等)。none 时退化为标准 AllReduce,拆分不发生。
代码依据 layers/communicator.py:369-386:
if context.is_layer_sparse and not get_moe_a2a_backend().is_none():
return ScatterMode.SCATTERED # → RS + AG 路径
return ScatterMode.FULL # → AllReduce 路径4.3 MoE 段和通信总账(一层)
MoE 夹在 RS 和 AG 中间:每 rank 拿到 1⁄4 tokens 后,dispatch A2A 按每 token 的目标 expert 路由到持有该 expert 的 rank,expert FFN 本地算(每 rank 64 experts),combine A2A 再送回原 rank。两次 A2A 完全对称,图 4 中段的两个绿色容器就是这对镜像。
一层的全部通信:
| 通信 | 组大小 | 位置 |
|---|---|---|
| 1× ReduceScatter | attn_tp=4 | o_proj 后 |
| 1× EP dispatch A2A | EP=4(单副本 world) | MoE 入口,按 expert 路由 token |
| 1× EP combine A2A | EP=4 | MoE 出口,送回原 rank |
| 1× AllGather | attn_tp=4 | MoE 后,补齐 AR 后半段 |
| 1× AllGather(仅末层) | TP=4 | LM Head vocab 拼回 |
副本间通信:零——这是 replica-level DP 的本质。
4.4 TP 会切到 MoE 层吗?
先澄清名字:启动参数 —tp N 是 world size(总卡数),不等于”MoE 层的 TP”。MoE 有自己的三个维度:
tp_size(world) = moe_ep_size × moe_tp_size × moe_dp_size| 维度 | 切什么 | 如何设 |
|---|---|---|
| moe_ep_size | experts 列表(n_experts 分到 N rank,每 rank 持 n_experts/ep 个完整 expert) | 用户指定(—ep-size) |
| moe_tp_size | 单个 expert 权重(W_gate/W_up/W_down 按 intermediate 再切) | 自动推导 = tp / ep / moe_dp |
| moe_dp_size | MoE 副本(world 切成 N 份独立 MoE,副本间不交换 token) | 用户指定(—moe-data-parallel-size,默认 1) |
所以”TP 会切到 MoE 吗”精确版是:moe_tp_size 配成 1 还是 >1?
配置 A:moe_tp = 1(默认,专家多+小)
- 每个 expert 完整放单 rank,MoE 层只有 EP dispatch/combine,无 AllReduce。
- 例:DeepSeek-V3(256 experts,单 expert ~1.5 GB),—tp 16 —ep-size 16 → moe_tp = 16/16/1 = 1,每 rank 持 16 个完整 expert。
- 单 expert 本身不大(比 attention Wq 还小),再切 TP 收益微小、多一次 AR——所以大 MoE 默认不切。
配置 B:moe_tp > 1(expert 少+大)
- 单 expert 太大装不下时,把 expert 内部按 TP 切。
- 例:Mixtral-8×7B(8 experts,单 expert 较大),—tp 16 —ep-size 8 → moe_tp = 2,每 rank 持 1 个 expert 的一半权重。
- MoE 层多一次 MOE_TP AllReduce(_MOE_TP 组内,size = moe_tp),FFN 后合并 partial——语义同标准 TP AR,只是组更小。
判断法则:看单 expert 能否塞进单卡。多而小(DeepSeek 类)→ moe_tp=1;少而大(Mixtral 类)→ moe_tp>1。启动后 mlp.experts.N.gate_proj.weight.shape 能验证是否被切。
4.5 moe_dp_size 独立参数
moe_dp_size 不是从 tp/dp/cp 推导,是用户主动选的:--moe-data-parallel-size N(默认 1)。语义是”把 world 切成 N 份独立 MoE 副本,副本间不做 EP A2A”。
约束(server_args.py:2896-2918):
- ep_size × moe_dp_size ≤ tp_size(等号当 ep_size > 1)
- attn_cp_size != moe_dp_size 时必须 moe_dp_size == 1
| 场景 | moe_dp_size | 说明 |
|---|---|---|
| 默认 MoE 全域 EP | 1 | 最常见,专家摊最散 |
| MoE A2A 带宽紧 → 复制权重省通信 | = attn_dp_size | 副本级 DP,副本间零 A2A |
| CP + MoE | 保持 1 | CP 的 token 合/切靠 _MOE_DP = _ATTN_CP 别名(见 §7.8) |
关键:绝大多数部署保持默认 moe_dp_size = 1。CP 与 MoE 的交互靠代码别名(parallel_state.py:1925-1929)而不是调这个参数。
4.6 SGLang vs vLLM:DP + EP 语义分歧
同一组参数 --tp 4 --dp 4 --enable-ep-moe 在两框架里行为完全不同,搬配置脚本容易踩坑。
| SGLang | vLLM | |
|---|---|---|
| —dp 4 默认语义 | 4 个独立副本(不开 DP Attention) | 真实 DP 并行维(自动启 Data Parallel attention) |
| EP 默认上限 | ep ≤ tp(单副本内) | ep ≤ dp × tp × cp(跨维度) |
| 扩大 EP 的开关 | —enable-dp-attention(必须加) | 默认就是 |
| Attention 层通信 | A2A 替代 AllReduce(DP Attention 开启后) | 保留 AllReduce + SP 切 token 入 MoE |
| 跨机性能 | ✓(消除 AR) | ⚠(AR 还在) |
判断经验:看 —dp 时是否需要额外开关让 DP 变”真实并行维”。SGLang 需要(—enable-dp-attention),vLLM 不需要(默认)。
DP Attention 不是 SGLang 独有——是 MoE 推理社区通用术语,起源于 DeepSeek V2/V3 技术报告,vLLM 官方文档里叫 “Data Parallel attention”。但实现机制不同(见 §5)。
5. DP Attention
一句话:MoE 跨机推理场景,保住 attention 的小 TP + 放开 MoE 的大 EP 的标准姿态。
好处
- 用 RS/AG(SGLang)或 A2A 替代 world 级 AllReduce → 跨机带宽友好
- 解耦 Attention 与 MoE 并行策略:Attention 走 attn_tp=4,MoE 独立走 EP=16
- KV cache 按 head 切、请求绑 DP 组(而非单卡),负载天然均衡
代价
- Attention 权重按 attn_tp 小组切(不是世界 TP)→ 权重在每个 DP 组内重复一份
- 仅适合 MoE 推理(Dense 用标准 TP 就够)
- 依赖 dp_size > 1,DP=1 用不上
图解
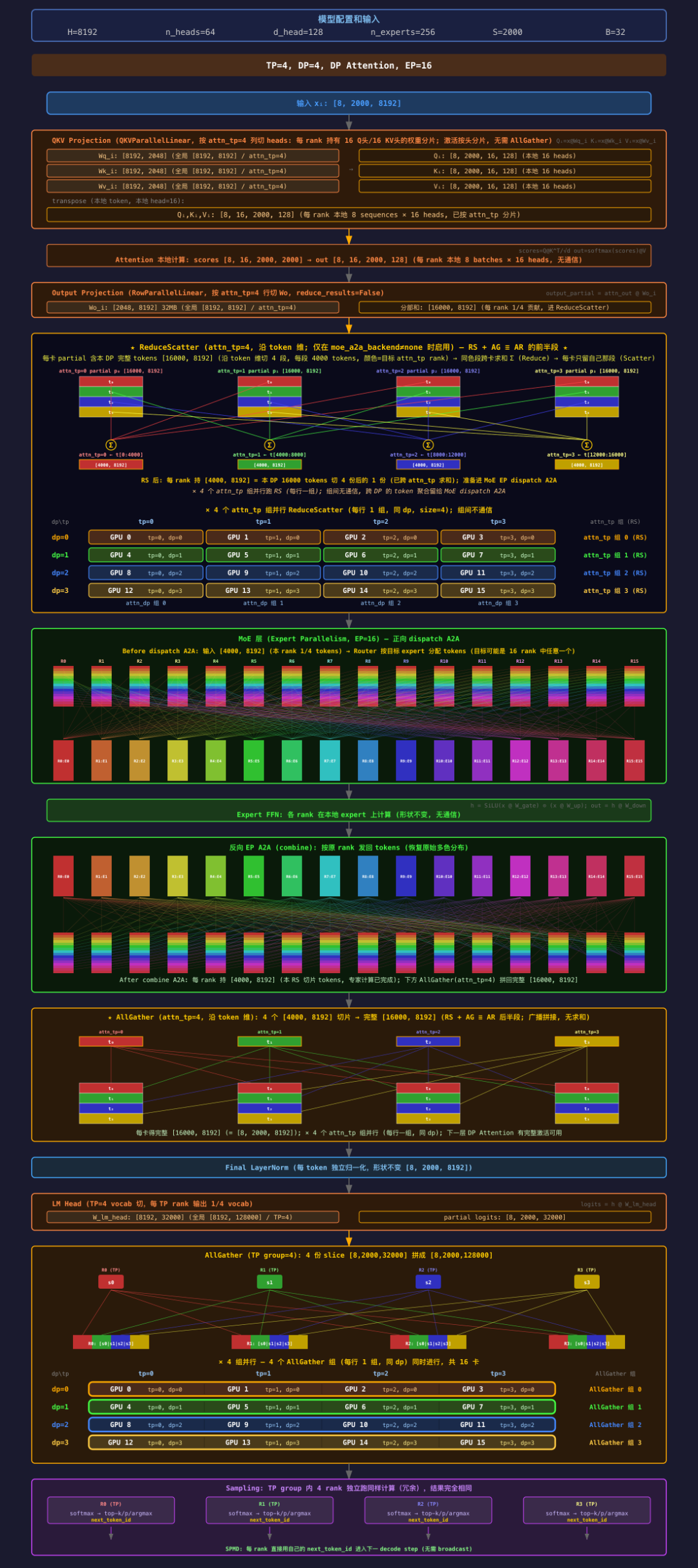
图 5 TP=4,DP=4,DP Attention,EP=16,world=16(典型 2×8 跨机部署)
5.1 为什么要开:三方案对比
场景:MoE 模型、16 卡跨 2 机,MoE 层铁定用 EP=16(专家并行无争议)。Attention 层怎么并行?
| 方案 A:Plain DP | 方案 B:TP Attention(world=16) | 方案 C:DP Attention | |
|---|---|---|---|
| 每卡 attention 权重 | 完整 | 1⁄16 | 完整(在 attn_tp 组内切 1/4) |
| 每卡 heads | 全部 64 | 4(64/16,太碎) | 16(64/4,合理) |
| Attention 通信 | 无 | 每层 AR(world=16,跨机慢) | 每层 RS + AG(attn_tp=4,可对齐 NVLink) |
| KV cache 布局 | 按请求绑卡 | 按 head 切 × 全 batch | 按 head 切 × 本 DP 组 batch |
| MoE 能独立选 EP 吗? | ✓ | ✗(强制 MoE 也 TP) | ✓ |
方案 A 的问题:每卡只握 B/16 请求的 token 进 MoE,expert GEMM 跑不满;KV 绑卡无法负载均衡。
方案 B 致命耦合:TP attention 输出是 [B, S, H/16] 的 partial,MoE 必须在同 TP 组消费 → MoE 被迫也用 TP,但专家数 ≫ 卡数,强塞 TP 把 expert 切碎效率暴跌。
方案 C 解法:attention 保持 attn_tp=4 的小组切头,MoE 独立跑 world=16 的 EP。正交。
5.2 核心硬收益:expert 权重显存
对 mimo-v2 / DeepSeek-V3 这种 256 experts 的大 MoE:
| 配置 | EP | experts/rank | expert 权重/rank(~1.5 GB bf16 × expert) |
|---|---|---|---|
| Replica DP(EP4,图 4) | 4 | 64 | ~96 GB ❌ 80 GB H100 放不下 |
| DP Attention(EP16,图 5) | 16 | 16 | ~24 GB ✓ |
EP=16 是 DeepSeek-V3 能塞进 80 GB 卡的唯一路径,而 EP=16 又不想让 attn_tp 拉到 16(头不够切 + AR 跨机爆炸)→ DP Attention 是唯一合理组合。
5.3 两个关键实现细节
attn_tp_size 不等于 world tp_size(mimo_v2.py):
self.qkv_proj = QKVParallelLinear(..., tp_size=attn_tp_size) # = 4, 不是 world 16
self.o_proj = RowParallelLinear(..., tp_size=attn_tp_size, reduce_results=False)attn_tp_size = tp_size / attn_dp_size = 16/4 = 4,和 §4(EP4)配置下的 attn_tp=4 一样——per-rank attention 代码路径完全相同,唯一差别在 MoE 的 EP 组大小。
Attention 段零 A2A:旧描述里”DP Attention = token↔head A2A 交换”在 SGLang mimo-v2 里不存在。只有 RS + AG 替代 o_proj 后的 AllReduce,跨 rank 的 token/head 交换从头到尾没有。
5.4 16-GPU 物理拓扑(图 5 RS / AG 容器内的 4×4 网格)
tp=0 tp=1 tp=2 tp=3 ← attn_dp 组(同 tp,跨 dp)
dp=0 GPU 0 GPU 1 GPU 2 GPU 3 ┐
dp=1 GPU 4 GPU 5 GPU 6 GPU 7 │ attn_tp 组(同 dp,跨 tp)
dp=2 GPU 8 GPU 9 GPU 10 GPU 11 │ ← RS / AG 就在此组
dp=3 GPU 12 GPU 13 GPU 14 GPU 15 ┘world_rank = dp_rank × attn_tp + tp_rank。
| 组 | 成员 | 图 5 中的角色 |
|---|---|---|
| attn_tp 组(行) | 同 dp 的 4 张卡 | RS / AG / LM Head vocab AG(—enable-dp-lm-head 时) |
| attn_dp 组(列) | 同 tp 的 4 张卡 | 无直接通信——仅作为 batch 分片的拓扑标签 |
| 全 world 组 | 所有 16 卡 | MoE dispatch / combine A2A、LM Head AG(默认) |
关键:attention 的通信域(attn_tp=4)和 MoE 的通信域(world=16)完全正交,一个跑局部 reduce/gather,一个跑全域 dispatch/combine。
5.5 KV cache 布局
每 DP 组(= 1 个 attn_tp 组 = 4 卡)处理 global batch 的 1/4(8 seq/组):
DP 组 0 (GPU 0-3): sequences 0-7
DP 组 1 (GPU 4-7): sequences 8-15
...每卡 KV cache 形状: [8 seq, 16 kv_heads, S, 128]
↑ 本 DP 组 batch ↑ attn_tp 切头
per-rank KV cache 形状和 EP4 完全相同,差别只在”这 4 卡在 world 里的位置”。请求和 DP 组绑定,不能跨组迁移 KV —— 调度器的负载均衡粒度是”DP 组之间”(非过去说的”按 head 全局分布”)。
5.6 名字的误导
“DP Attention” 的名字容易让人误解——attention 层本身并没”做 DP”,per-rank 还是算自己 attn_tp 份额的 heads,只是 batch 被 DP 切了。真正发生的是 “attention 保小 TP(attn_tp = tp/dp),MoE 放大 EP(到 world 大小)”,让 MoE 从 attention TP 束缚里释放出来(§5.1 方案 C vs 方案 B 的核心差异就在这)。
6. SP(Sequence Parallelism,序列并行)
一句话:TP 的激活显存补丁,把 TP 区域外的 LN/Residual 激活也按 S 切,不减通信但多 1 次 collective。
好处
- 消除 TP 区域外(LN / Residual)的激活冗余 → 单层峰值激活 ÷ N
- 训练首选(激活要保留给反向,省的就是显存上限)
- 不引入新通信域(AG / RS 仍用 TP group)
代价
- 必须依附 TP,不是独立维度
- 通信次数 +1:1× AR 变 1× AG + 1× RS,字节数相同但 collective 多 1 次
- 推理收益小(激活用完即丢),训练价值大
图解
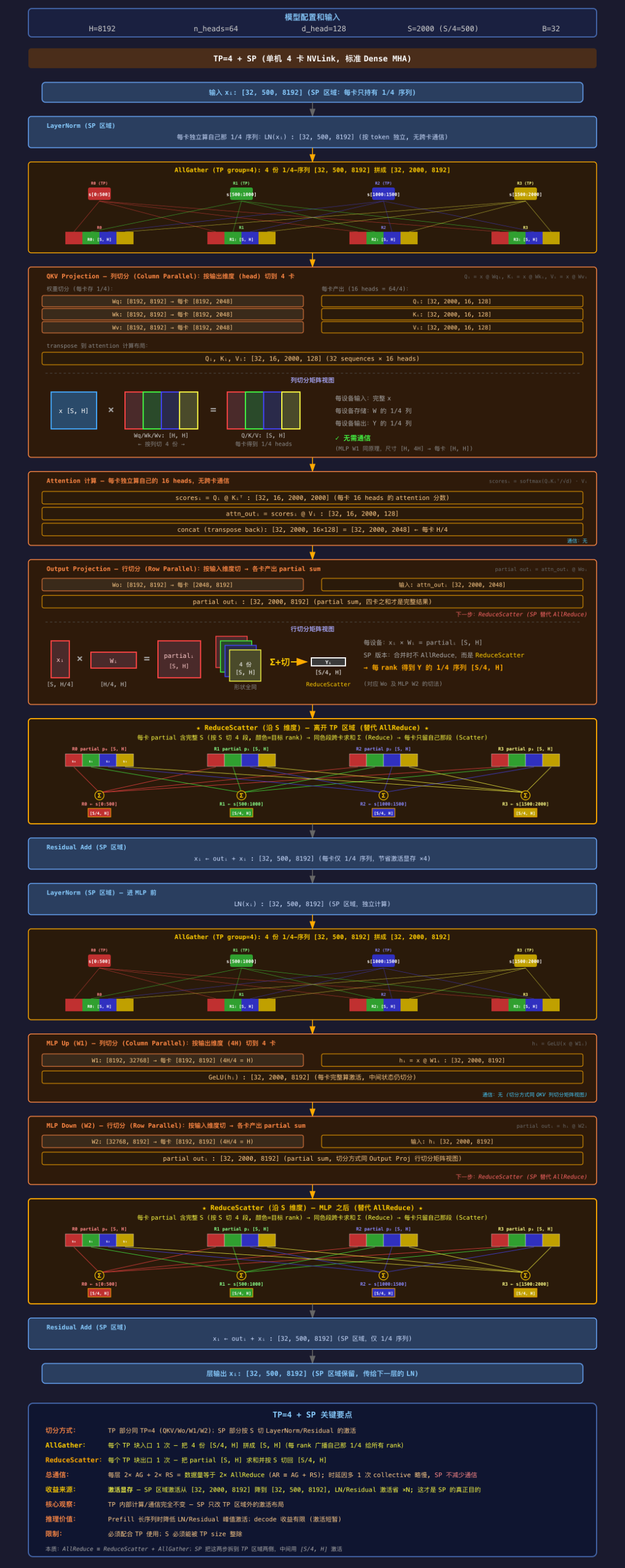
图 6 TP=4 + SP,标准 Dense MHA
颜色:
- 🟦 SP 区(LN / Residual,[32, 500, 8192] per rank)
- 🟧 TP 区(QKV / Attention / MLP,[32, 2000, 8192])
- ⭐ 集合通信
6.1 核心机制:AR = AG + RS 拆两半
标准 Transformer 一层天然分两区:
x → [LayerNorm] → [QKV → Attention → Out Proj] → [Residual] → 输出
🟦 SP 🟧 TP 🟦 SP
只能按 S 切 可以按 H 切 只能按 S 切标准 TP 的漏洞:🟦 区每卡存完整 [S, H],N 卡冗余 N 份。
SP 的方案:用和 §4.2 同一个恒等式 AllReduce ≡ ReduceScatter + AllGather,但换一种拆法——把 TP 的每次 AR 拆成 AG(TP 入口)+ RS(TP 出口),中间夹 🟧 TP 区,两侧留 🟦 SP 区只存 [S/4, H] 小激活:
🟦 [S/4, H] → LayerNorm → ⭐AG↗ → 🟧 [S, H] 🟧 [S, H] → QKV → Attn → OutProj → partial [S, H] → ⭐RS↘ → 🟦 [S/4, H] → ResidualAttention 块和 MLP 块同型,两者都是 AG → 列切 → 行切 → RS。一层 2× AG + 2× RS。
6.2 每卡形状(同图)
| 阶段 | 区 | 形状 |
|---|---|---|
| 输入 / LN / Residual | 🟦 | [32, 500, 8192](1/4 序列) |
| 进 TP 区(AG 后) | 🟧 | [32, 2000, 8192] |
| Attention scores | 🟧 | [32, 16, 2000, 2000](1⁄4 heads) |
| 出 TP 区(RS 前,partial) | 🟧 | [32, 2000, 8192] × 4 份 |
| 出 TP 区(RS 后) | 🟦 | [32, 500, 8192] |
6.3 收益账
🟦 SP 区激活(LN + Residual, 单层, fp16):
- 无 SP: 2 × [32, 2000, 8192] × 2 = 2 GB ← 冗余
- 有 SP: 2 × [32, 500, 8192] × 2 = 512 MB
节省: 1.5 GB / 层 × N 层 ← 核心收益
通信:
- 无 SP: 2× AllReduce / 层(2 个 collective)
- 有 SP: 2× AG + 2× RS / 层(4 个 collective, 字节数相同)
SP 不是通信优化——字节数相同,collective 次数翻倍(2→4),每次同步开销叠加,墙钟时间略慢。价值全在激活显存。
6.4 推理里什么时候有用
- 训练:激活保留反向,SP 几乎标配。
- 推理:
- Prefill 长 prompt(32K+):🟦 区激活峰值大,SP 能显著压峰 ✓
- 连续批处理 / 高并发:多请求合并总 token 量大,峰值可压 ✓
- Decode 单 token:S=1,收益 ~0 ✗
SP 的价值在训练 / prefill 峰值优化,CP 才是长 context 推理的主力(见 §7)。SP vs CP 的详细对比并入 §7.2。
7. CP(Context Parallelism,上下文并行)
一句话:把序列切到多卡,每卡只算一段 token 的 attention,通过 Ring 通信在 attention 内部凑齐跨段 K/V 依赖——专治超长 context。
好处
- 支持超长序列(32K / 128K+ tokens),是长上下文推理的主力方案
- KV cache 天然按 seq 分布在 CP 组内多卡 → 单卡放不下的长 seq 也能跑
- 独立并行维度(和 TP/DP/PP 正交),可以自由叠加
- Ring Attention 能让通信和计算 overlap,跨机也能打
- Prefill 阶段长 prompt 并行算 attention,显著降 prefill 延迟 / 峰值
代价
- 依赖 attention kernel 支持”分段累积”(Flash Attention online softmax 那套)
- Decode 阶段每 token 要在 CP 组内归约,延迟有固定开销
- 短序列开 CP 纯粹拖累(通信固定成本 > 切分收益)
- 实现复杂度高(Ring 调度、边界处理、causal mask 的负载均衡)
- 和 DP / TP 共享 world 预算(SGLang 里 attn_tp_size = tp_size / (dp × cp)),CP 越大 attn_tp 越小
图解

图 7 CP 形状详解
7.1 核心思想
把序列切到多卡,每卡只算一段 token 的 Q/K/V,在 attention 内部通过通信凑齐跨段依赖。
7.2 SP vs CP:序列并行的两种路向
| SP(Sequence Parallelism) | CP(Context Parallelism) | |
|---|---|---|
| 切什么 | TP 区域外的激活(LN/Residual) | Attention 内部的 Q/K/V token |
| 在哪通信 | 靠 TP 域的 AG/RS | 在 attention 内部的 Ring 通信 |
| 目标 | 消除激活冗余显存 | 支持超长序列(32K+) |
| 推理价值 | 小(激活用完即丢) | 大(长 context 唯一解) |
| 训练价值 | 大(激活保留反向) | 大(长序列训练) |
| 难度 | 低(和 TP 集成) | 高(Ring、边界、causal mask) |
推理里 SP 主要压峰值(prefill),CP 主力撑长 context(decode)。两者互补,可叠加(TP + SP + CP)。
原文链接
本文转载自微信公众号文章:大模型推理夯实:并行策略图解
本文由 OpenClaw 自动保存和整理,图片已本地化存储。